
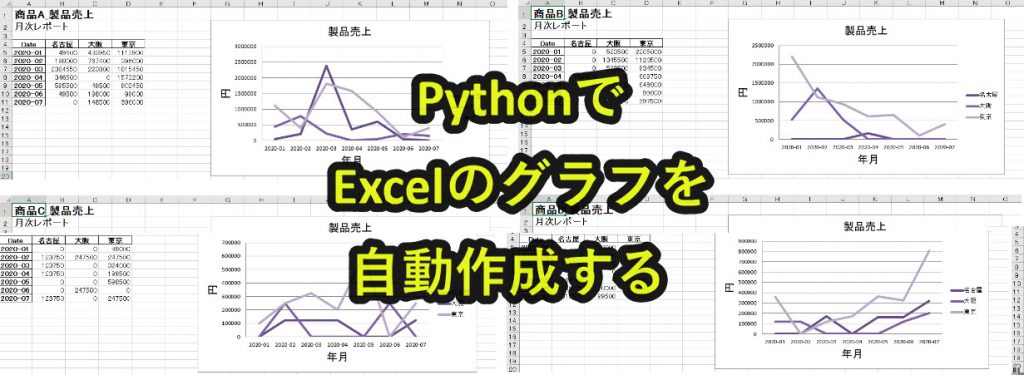
Pythonを使うとエクセルのデータを読み込み、グラフ化することができます。
今回は単純にグラフ化するだけではなく、データ解析を行ってグラフを作成するところまで含めて行います。
・データごとにグラフを作成する
・ファイルを分けて保存する
それでは以下で詳しく紹介していきます。
目次
- 1 ExcelデータをPythonで処理するプログラムの概要
- 2 Pythonプログラムを実行するための準備
- 3 Pythonプログラム解説
- 3.1 プログラム1|ライブラリの設定
- 3.2 プログラム2|エクセルを読み込む
- 3.3 プログラム3|エクセルをpandasで読み込む
- 3.4 プログラム4|「Product」「Area」「Date」のそれぞれの列で重複を削除したリストを作成
- 3.5 プログラム5|保存ファイル名を作成
- 3.6 プログラム6|「Product」ごとにピボットテーブルを作成
- 3.7 プログラム7|プログラム6のエクセルを開く
- 3.8 プログラム8|エクセルへ文字列を出力
- 3.9 プログラム9|グラフを生成
- 3.10 プログラム10|グラフの表示を整える
- 3.11 プログラム11|グラフを表示
- 3.12 プログラム12|エクセルを新しい名前で保存
- 4 Pythonについて詳しく理解したいなら
ExcelデータをPythonで処理するプログラムの概要
今回はPythonで「Product」ごとにデータを解析してグラフを作成するプログラムを解説します。
実際に以下の作業をpythonで行うことを目指します。
1. Excelのデータを読み込む
2. 「Product」ごとにデータを分けて折れ線グラフを作成する
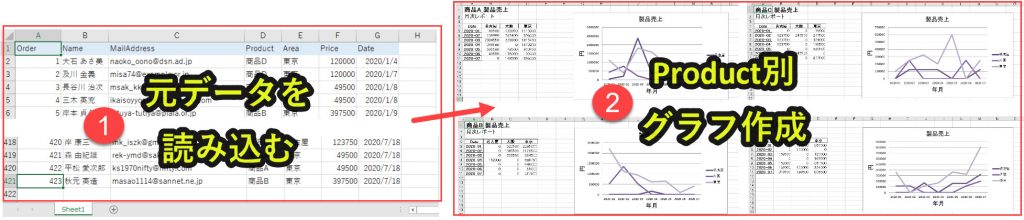
エクセルの読み込みとデータ分析はPandasというライブラリを使い、グラフ作成はopenpyxlを使っていきます。
詳しいプログラム解説は後半で行います。
Pythonプログラムを実行するための準備
事前の準備として、pandasとopenpyxlを使えるようにライブラリ設定をします。
準備1|pandasモジュールのインストール
1. コマンドプロンプトを起動(ショートカットキー[windows] + [R])
2. 「cmd」と記入して[Enter]
3. 「pip install pandas」と入力して[Enter]
4. インストール完了
これでインストールが完了し、pandas使えるようになります。
準備2|openpyxlモジュールのインストール
1. コマンドプロンプトを起動(ショートカットキー[windows] + [R])
2. 「cmd」と記入して[Enter]
3. 「pip install openpyxl」と入力して[Enter]
4. インストール完了
それでは以下でプログラムを解説していきます。
Pythonプログラム解説
この記事で紹介するプログラムを解説しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
#プログラム1|ライブラリの設定 import pandas as pd from datetime import datetime import openpyxl as px #プログラム2|エクセルを読み込む filepath = 'sample.xlsx' #プログラム3|エクセルをpandasで読み込む df = pd.read_excel(filepath) df['Date'] = pd.to_datetime(df['Date']).dt.strftime("%Y-%m") #プログラム4|「Product」「Area」「Date」のそれぞれの列で重複を削除したリストを作成 products = sorted(list(df['Product'].unique())) areas = sorted(list(df['Area'].unique())) dates = sorted(list(df['Date'].unique())) #プログラム5|保存ファイル名を作成 now = datetime.now() hiduke = now.strftime('%Y-%m-%d') #プログラム6|「Product」ごとにピボットテーブルを作成(index=Date, 列=Area, 値=Price(累計値)) for product in products: filtered = df[df['Product'] == f'{product}'] sales = pd.pivot_table(df, index=filtered['Date'], columns='Area', values='Price', aggfunc='sum',fill_value=0) filepath = f'{hiduke}_{product}.xlsx' sales.to_excel(filepath,sheet_name='製品売上',startrow=3) #プログラム7|プログラム6のエクセルを開く wb = px.load_workbook(filepath) ws = wb['製品売上'] #プログラム8|エクセルへ文字列を出力 ws.cell(row=1, column=1).value = f'{product}_製品売上' ws.cell(row=1, column=1).font = px.styles.Font(size=18, bold=True) ws.cell(row=2, column=1).value = '月次レポート' ws.cell(row=2, column=1).font = px.styles.Font(size=16, bold=True) #プログラム9|グラフを生成 chart = px.chart.LineChart() data = px.chart.Reference(ws, min_col=2, max_col=len(areas)+1, min_row=4, max_row=len(dates)+4) categories = px.chart.Reference(ws, min_col=1, max_col=1, min_row=5, max_row=len(dates)+4) chart.add_data(data, titles_from_data=True) chart.set_categories(categories) #プログラム10|グラフの表示を整える chart.style = 14 chart.title = '製品売上' chart.y_axis.title = '円' chart.x_axis.title = '年月' chart.height = 9 chart.width = 16 #プログラム11|グラフを表示 ws.add_chart(chart, "G2") #プログラム12|エクセルを上書き保存 wb.save(filepath) |
以下で詳しく説明しています。
プログラム1|ライブラリの設定
|
1 2 3 4 |
#プログラム1|ライブラリの設定 import pandas as pd import openpyxl as px from datetime import datetime |
プログラム解説
|
1 2 3 4 |
#解説 ・pandas|データ解析をするライブラリ ・openpyxl|エクセルなどのデータを操作するためのライブラリ ・datetime|日付を操作するためのライブラリ |
このプログラムでは、3つのライブラリ設定をします。
まずpandasでピボットテーブルでデータ解析をします。
openpyxlでエクセルの折れ線グラフを作成します。
datetimeでエクセルのファイル名で使います。
プログラム2|エクセルを読み込む
|
1 2 |
#プログラム2|エクセルを読み込む filepath = 'sample.xlsx' |
プログラム解説
|
1 2 |
#解説 Pythonファイルと同じフォルダ内の「sample.xlsx」のフォルダパスを取得 |
この事例では、対象のエクセルファイルをpythonプログラムと同じフォルダに保存してあります。
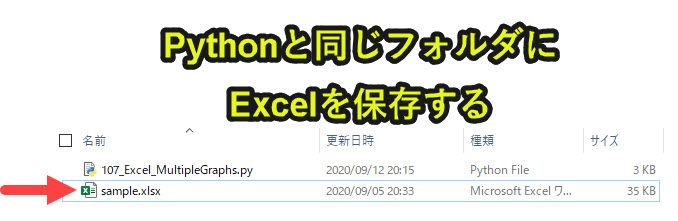
もしpythonを保存してあるフォルダと異なるフォルダのExcelファイルを結合したい場合は、「C:\Users\xxx\Dropbox\Python\Program\100_Excel\104_Excel_fileTenki」のようなフルパスを設定する方法があります。
プログラム3|エクセルをpandasで読み込む
|
1 2 3 |
#プログラム3|エクセルをpandasで読み込む df = pd.read_excel(filepath) df['Date'] = pd.to_datetime(df['Date']).dt.strftime("%Y-%m") |
プログラム解説
|
1 2 3 |
#解説 変数dfにpandasでエクセルファイルを読み込む dfのDate列を「YYYY-mm」型に変換する |
まずはpd(pandas)でエクセルファイルを読み込んで、dfとしてデータを取得します。
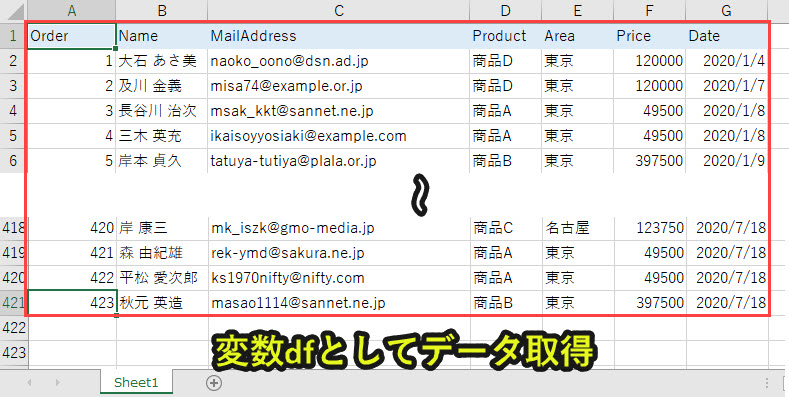
続いて、月ごとにデータを分析するため、Date列の日付を「YYYY-mm」型に変換します。

これにより、月ごとのデータとして解析がやりやすくなります。
プログラム4|「Product」「Area」「Date」のそれぞれの列で重複を削除したリストを作成
|
1 2 3 4 |
#プログラム4|「Product」「Area」「Date」のそれぞれの列で重複を削除したリストを作成 products = list(df['Product'].unique()) areas = list(df['Area'].unique()) dates = list(df['Date'].unique()) |
プログラム解説
|
1 2 3 4 |
#解説 変数productsに「Product」列のデータの重複削除したリストを取得 変数areasに「Area」列のデータの重複削除したリストを取得 変数datesに「Date」列のデータの重複削除したリストを取得 |
それぞれの重複削除したリストは以下です。
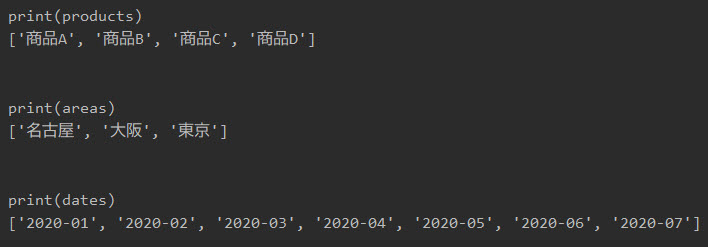
プログラム5|保存ファイル名を作成
|
1 2 3 |
#プログラム5|保存ファイル名を作成 now = datetime.now() hiduke = now.strftime('%Y-%m-%d') |
|
1 2 3 |
#解説 変数nowに今の日時を取得 変数hidukeを「YYYY-mm-dd」型で今の日付を取得 |
それぞれの変数は以下です。
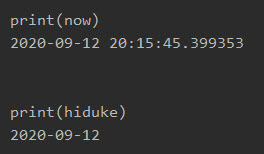
プログラム6|「Product」ごとにピボットテーブルを作成
|
1 2 3 4 5 6 |
#プログラム6|「Product」ごとにピボットテーブルを作成(index=Date, 列=Area, 値=Price(累計値)) for product in products: filtered = df[df['Product'] == f'{product}'] sales = pd.pivot_table(df, index=filtered['Date'], columns='Area', values='Price', aggfunc='sum',fill_value=0) filepath = f'{hiduke}_{product}.xlsx' sales.to_excel(filepath,sheet_name='製品売上',startrow=3) |
プログラム解説
|
1 2 3 4 5 6 |
#解説 変数productsの要素を一つずつ処理 変数filteredに「Product」列で変数productに一致するデータのみフィルターして取得 変数salesにdfをピボットテーブルを行う(インデックス=「filtered['Date']」, 列=「Area」, 値=「Price」,累計値で , 値がないときは0で埋める) 変数filepathに保存したいエクセルファイル名を作成 変数salesをエクセルに書き出す(保存ファイル名はfilepath, シート名は「製品売上」,データは4行目に書き出す(0が起点のため、startrow=3で4行目開始となる)) |
今回のデータでは、Product(ここでは商品A, 商品B, 商品C, 商品D)ごとに繰り返し処理を行う。
変数filteredでProductごとに分けたデータを取得する。
f'{product}’で変数productを文字列として扱うことができる。たとえばproductが「商品A」のとき、商品Aも文字列を取得できる。

続いて、変数salesに「Date」の月ごとのデータをArea別にPriceを累算して出力する。
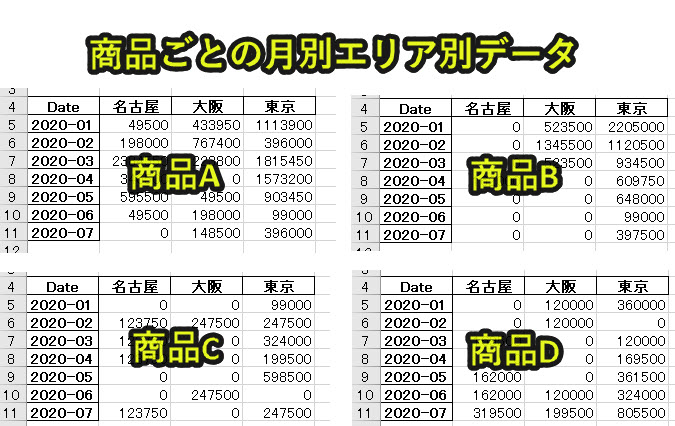
ちなみに累算する値がない場合、データに穴ができてしまうので、fill_value=0で0で埋めるようにしています。
変数filepathのandasの機能として.to_excelでデータをエクセルに変換することができます。
また、f'{hiduke}_{product}.xlsx’で変数hiduke、productを文字列として扱うことができる。
たとえばhidukeが「2020-09-12」で、productが「商品A」のとき、filepath=「2020-09-12_商品A.xlsx」となる。
プログラム7|プログラム6のエクセルを開く
|
1 2 3 |
#プログラム7|プログラム6のエクセルを開く wb = px.load_workbook(filepath) ws = wb['製品売上'] |
プログラム解説
|
1 2 3 |
#解説 変数wbで「filepath」のエクセルを読み込む(プログラム6で書き出したエクセル) 変数wsに「製品売上」シートを設定する |
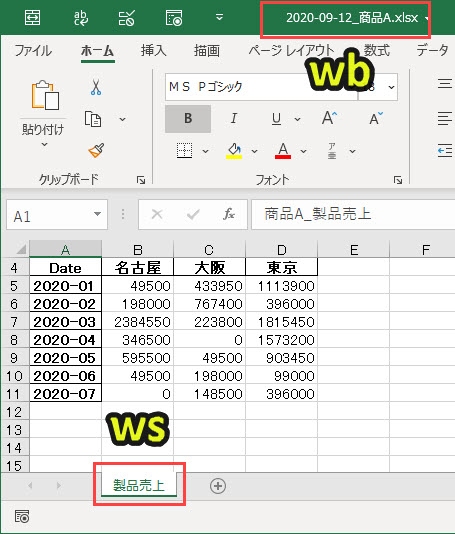
プログラム8|エクセルへ文字列を出力
|
1 2 3 4 5 |
#プログラム8|エクセルへ値を書き出す ws.cell(row=1, column=1).value = f'{product}_製品売上' ws.cell(row=1, column=1).font = px.styles.Font(size=18, bold=True) ws.cell(row=2, column=1).value = '月次レポート' ws.cell(row=2, column=1).font = px.styles.Font(size=16, bold=True) |
プログラム解説
|
1 2 3 4 5 6 |
#解説 #プログラム8|エクセルへ値を書き出す セルA1(1行目,1列目)にf'{product}_製品売上'を入力 セルA1(1行目,1列目)のフォントサイズ18で太字にする セルA2(2行目,1列目)に「月次レポート」を入力 セルA2(2行目,1列目)のフォントサイズ16で太字にする |
「f'{product}_製品売上’」は、product=「商品A, 商品B, 商品C, 商品D」がそれぞれ設定される。
したがって、product=商品Aのとき、「f'{product}_製品売上’」=「商品A_製品売上」となる
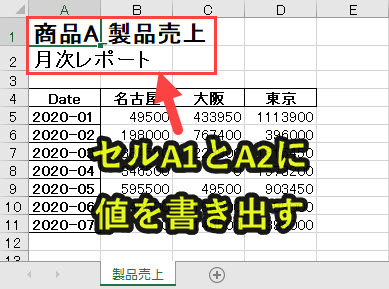
プログラム9|グラフを生成
|
1 2 3 4 5 6 |
#プログラム9|グラフを生成 chart = px.chart.LineChart() data = px.chart.Reference(ws, min_col=2, max_col=len(areas)+1, min_row=4, max_row=len(dates)+4) categories = px.chart.Reference(ws, min_col=1, max_col=1, min_row=4, max_row=len(dates)+4) chart.add_data(data, titles_from_data=True) chart.set_categories(categories) |
プログラム解説
|
1 2 3 4 5 6 |
#解説 折れ線グラフを作成 変数dataにデータ(B4を起点にした範囲)を設定 変数categoriesにデータ(A4を起点にした範囲)を設定 折れ線グラフのデータ範囲に変数dataを設定 折れ線グラフのカテゴリに変数categoriesを設定 |
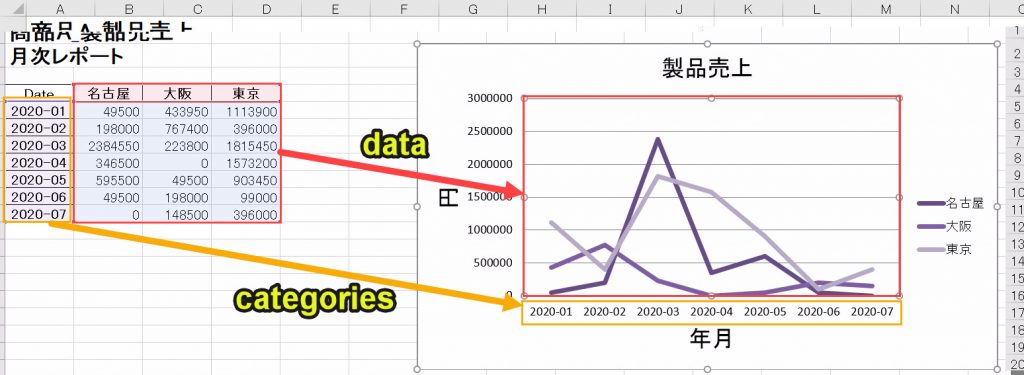
プログラム10|グラフの表示を整える
|
1 2 3 4 5 6 7 |
#プログラム10|グラフの表示を整える chart.style = 14 chart.title = '製品売上' chart.y_axis.title = '円' chart.x_axis.title = '年月' chart.height = 9 chart.width = 16 |
プログラム解説
|
1 2 3 4 5 6 7 |
#解説 グラフのテーマをタイプ14にする グラフのタイトルを「製品売上」にする Y軸の表示を「円」にする X軸の表示を「年月」にする グラフの高さを9にする グラフの幅を16にする |
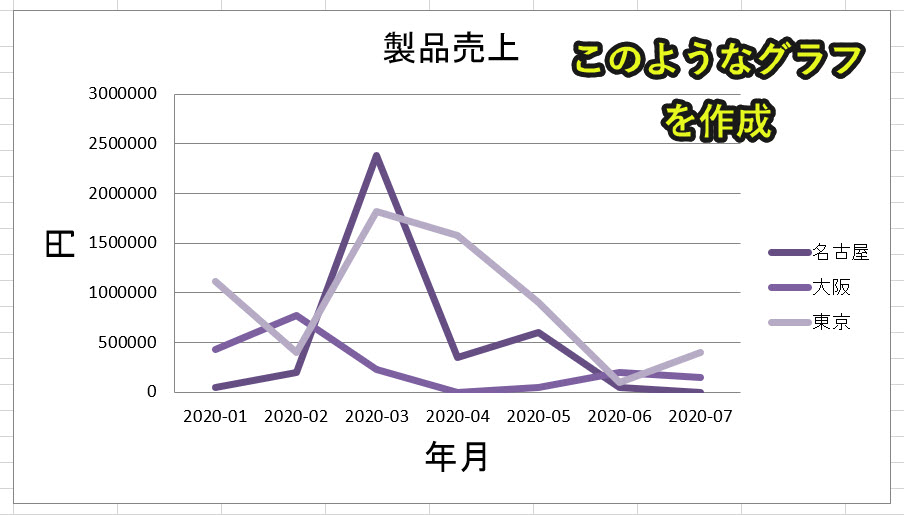
ちなみにchart.style=14の他の値にすると、グラフのスタイル(色など)が変わります。
プログラム11|グラフを表示
|
1 2 |
#プログラム11|グラフを表示 ws.add_chart(chart, "G2") |
プログラム解説
|
1 2 |
#解説 セルG2に折れ線グラフを出力する |
プログラム12|エクセルを新しい名前で保存
|
1 2 |
#プログラム12|エクセルを上書き保存 wb.save(filepath) |
プログラム解説
|
1 2 |
#開発 エクセルを上書き保存する |
実際にファイルを開いてみると、以下のように同じフォーマットでグラフを作成しています。
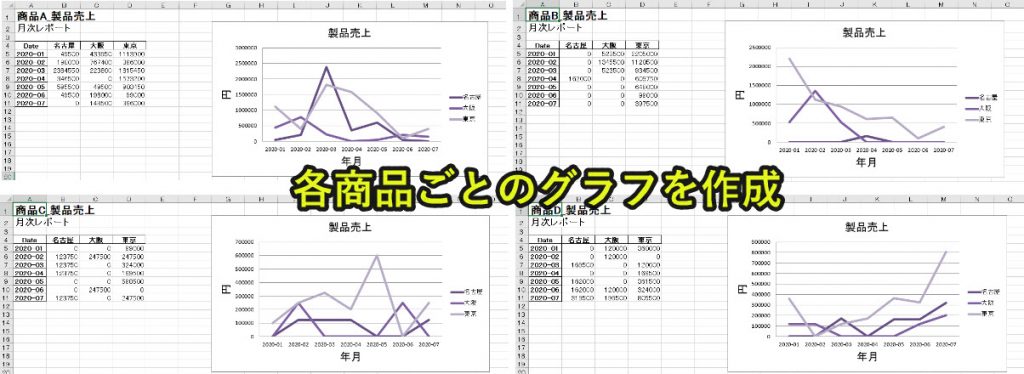
プログラムの解説はここまでです。
Pythonについて詳しく理解したいなら
Pythonを活用すると、仕事を効率化できる幅を広げることができます。
たとえば私が実際にPythonを活用して効率化してきた作業は以下の記事で紹介しています。
興味がある人は以下の記事もご覧ください。

Pythonの難易度などについては、以下で紹介しています。
勉強の参考になれば幸いです。
