

Pythonを使ってExcelのデータを分析したいとき、Pandasを使うとラクに処理できます。
普段の仕事では、Excelを開いて処理する人が多いですが、Pythonを使ってExcelをデータ分析する方がメリットが高いことがあります。
そこで、Pandasによるデータ分析のサンプルコードを事例を通じて解説していきます。
・PythonでExcel関数(sumifs, countifs, vlookupなど)の処理を実行
・Pythonでピボットテーブルで時系列(月別, 週別, 四半期別など)でデータ処理
目次
- 1 Pandaを使ってExcelでデータ分析するメリットとデメリット
- 2 3つの事前準備! PandasライブラリのインストールとExcelファイルのダウンロードなど
- 3 本記事で扱うExcelファイルとPythonファイルのダウンロード用フォーム
- 4 PandaでExcelを読み込む
- 5 Pandasでエクセルのsum関数・count関数を実行
- 6 Pandasで条件に合致したデータの件数・合計|countif、sumif
- 7 Pandasで特定の文字列を含んでいる行の件数・合計|countif、sumifではできない
- 8 Pandasで複数条件に合致したデータの件数・合計|countifs、sumifs
- 9 Pandasでsumproduct関数
- 10 Pandasでvlookup関数
- 11 Pandasピボットテーブル
- 12 Pandasで重複を削除
- 13 列内の全要素を抽出
- 14 Pandasでエクセルを書き出して保存する
- 15 Pythonについて詳しく理解したいなら
Pandaを使ってExcelでデータ分析するメリットとデメリット
3つのメリット
1. 細かいデータ分析ができる
2. エクセルファイルが壊れたり、見失ったりする
3. 他のライブラリとの組み合わせ(機械学習などと連携)
メリット1. 細かいデータ分析ができる
PandasはExcelでのデータ分析に比べて、細かい処理をしやすいです。
たとえば、Pythonにはgroupbyというプログラムがあります。
これを使うと、データの各要素について分析することができます。
これはエクセルだと機能がありません。
エクセルで処理できる関数は基本的にはPandasで使用可能です。
メリット2. エクセルファイルが壊れたり、見失ったりする
エクセルを開いて操作をしていると、データを書き換えてしまうことがあります。
そうすると、どれが元ファイルだったのかということになってしまう可能性があります。
またファイルの上書きや破損はなくとも、様々な処理をした結果、最新版が分からなくなったり、オリジナル版が埋もれてしまったりします。
よくあるのが、「最終版.xlsx」や「最終版2.xlsx」といったように最新版だらけになってしまうことです。
Pythonではエクセルファイルそのものを操作することはないので、エクセルファイルが壊れたり、見失ったりする心配はありません。
メリット3. 他のライブラリとの組み合わせ(機械学習などと連携)
他のライブラリとの連携しながら、様々な操作を行うことができるのがPythonでPandaを使うメリットです。
統計処理や機械学習と連携させることができることが可能です。
実際は、このような他のライブラリとの組み合わせがPandasを使う最大のメリットです。
3つのデメリット
1. エクセルに慣れている人が多い
2. データ量が少ないとき、Excelのほうが使いやすい
3. エクセルの機能で十分であることが多い
デメリット1. エクセルに慣れている人が多い
私の体感ですが、データ分析をするとき、Pythonを使う人よりExcelで処理を行う人のほうが圧倒的に多いです。
そうすると、人に仕事を渡すのが難しくなります。
Pythonプログラムでどれだけ素晴らしい処理ができたとしても、他の人に渡した途端、使い物にならなくなってしまうのです。
会社としてみれば、手順の平準化ができないため、良くない状況と言えます。
部署でPythonを使うというような特殊な環境でない限り、エクセルよりPythonとはなかなかならないでしょう。
デメリット2. データ量が少ないとき、Excelのほうが使いやすい
データ量が少ないとき、Pythonを使うよりエクセルで目視確認しながら作業するほうがやりやすいです。
理由は、エクセルのほうが視認性が高いからです。
大量のデータを扱うことがない限り、エクセルのほうがカンタンに処理できるのは否定できません。
デメリット3. エクセルの機能で十分であることが多い
正直に言って、エクセルの機能で十分にデータ処理できることが多いです。
それこそ、機械学習や統計処理をするような状況でないと、Pythonを使うメリットはそこまでありません。
それくらいエクセルは優秀と言えます。
ただ今後は、Pythonでデータ処理をして統計処理や機械学習のような処理を連携させる仕事も増えるかもしれません。
そのような状況になれば、Pythonでデータ処理をするメリットが注目されることになるかもしれません。
3つの事前準備! PandasライブラリのインストールとExcelファイルのダウンロードなど
1. Pandasライブラリのインストール
2. PythonファイルとExcelファイルを同じフォルダに保管する
3. 本記事で使用するExcelファイルのデータ
以下で詳しく紹介していきます。
事前準備1|Pandasライブラリのインストール
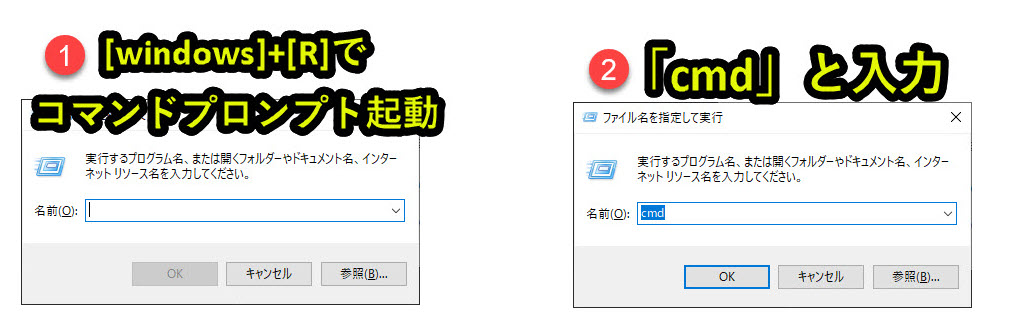
1. コマンドプロンプトを起動(ショートカットキー[windows] + [R])
2. 「cmd」と記入して[Enter]
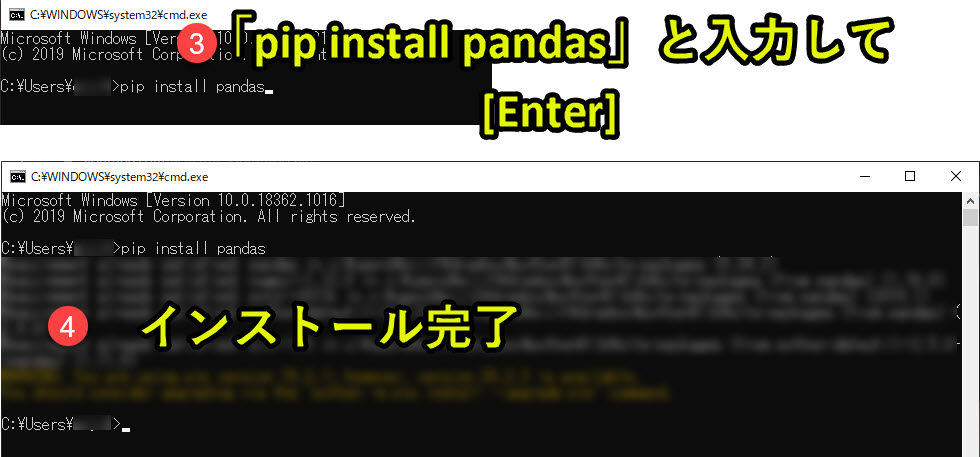
3. 「pip install pandas」と入力して[Enter]
4. インストール完了
これでインストールが完了し、pandas使えるようになります。
事前準備2|PythonファイルとExcelファイルを同じフォルダに保管する
本記事のプログラムをそのまま使いまわしたい場合は、PythonファイルとExcelファイルを同じフォルダに保管してください。
そうしないとエラーが出てしまいます。
理由は、本記事で扱うデータ分析のプログラムは、Pythonファイルと同じフォルダの「sample.xlsx」を読み込みようにしているからです。

もしデータ処理するエクセルファイルと、Pythonファイルを別フォルダに保管したい場合は、エクセルファイルのフルパスを入力するようにしてください。
事前準備3|本記事で使用するExcelファイルのデータ
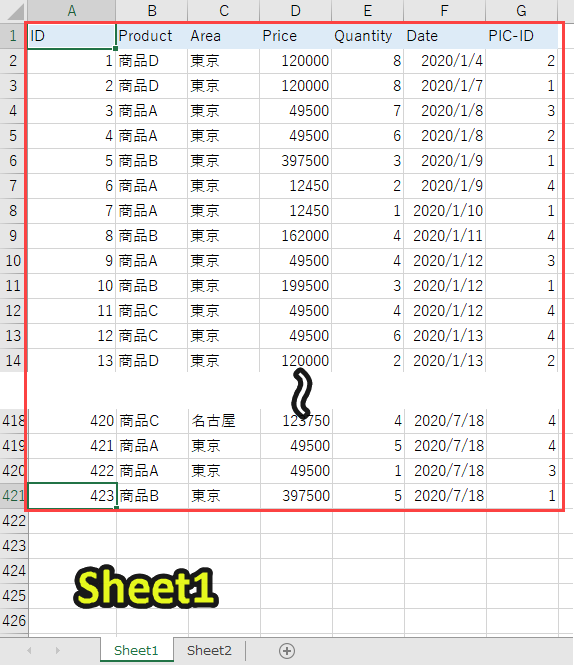
なお、ここで扱う「sample.xlsx」は以下のようなデータが入っています。
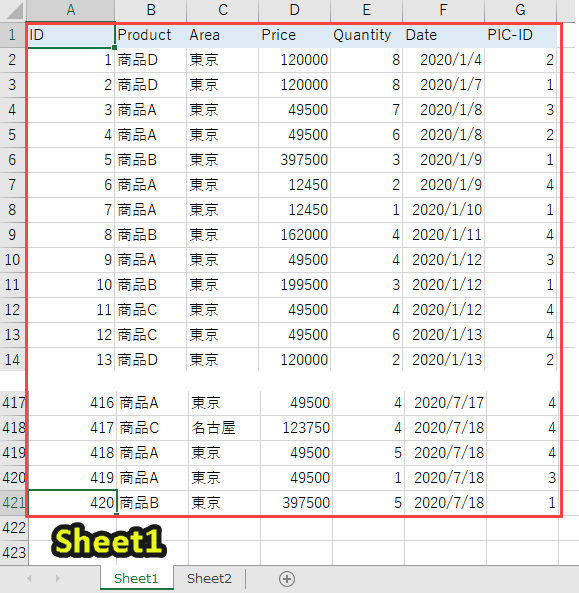
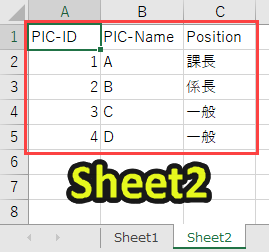
先にデータを見ておくと、以下のプログラムの内容が理解しやすくなるので、目を通しておくことをオススメします。
本記事で扱うExcelファイルとPythonファイルのダウンロード用フォーム
きちんと勉強するなら、本記事で扱うExcelファイルとPythonファイルをダウンロードしてみてください。
以下のフォームからダウンロード可能です。
フォームは準備中
PandaでExcelを読み込む
プログラム1|エクセルの読み込み
プログラム2|エクセルのシートを指定して読み込み
プログラム3|エクセルのシートを指定して読み込み(indexを指定しない)
プログラム4|データがないセル(NaN)を他の値で埋める
プログラム1|エクセルをpandasで読み込み
|
1 2 3 4 |
#プログラム1|エクセルの読み込み import pandas as pd df1 = pd.read_excel('sample.xlsx') print(df1.head()) |
プログラム解説
|
1 |
import pandas as pd |
pandasをpdで呼び出すようにします。
これでpandasライブラリを使用することができるようになります。
|
1 |
df1 = pd.read_excel('sample.xlsx') |
df1(変数)にエクセルを読み込みます。
今回扱うエクセルには2つのシートがありますが、シートを指定しない場合、「Sheet1」を読み込みます。
|
1 |
print(df1.head()) |
「df1.head()」とすることで、df1の上から5コ分のデータを表示します。
ここでは、「Sheet1」の上から5行のデータを出力します。

画面キャプチャーでは、Pycharmのキャプチャーを使っています。
プログラム2|エクセルのシートを指定して読み込み
|
1 2 3 4 5 6 |
#プログラム2|エクセルのシートを指定して読み込み import pandas as pd df2_1 = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df2_2 = pd.read_excel('sample.xlsx', sheet_name='Sheet2') print(df2_1.head()) print(df2_2.head()) |
プログラム解説
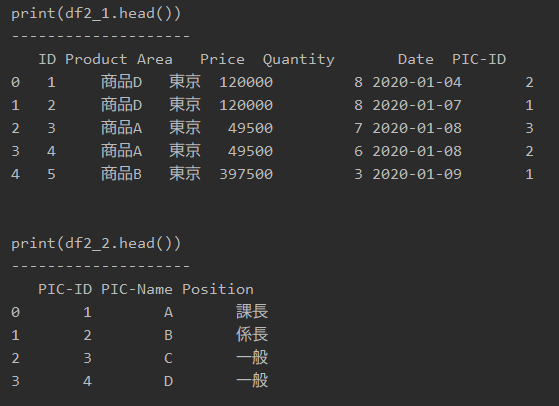
df2_2 = pd.read_excel(‘sample.xlsx’, sheet_name=’Sheet2′)
「sheet_name = ‘シート名’」とすると、シートを指定して読み込むことができます。
したがって、df2_1で「Sheet1」、df2_2で「Sheet2」でそれぞれのエクセルシートを読み込みます。
print(df2_2.head())
printで表示すると、以下のようになります。
プログラム3|エクセルのシートを指定して読み込み(indexを指定しない)
|
1 2 3 4 |
#プログラム3|エクセルのシートを指定して読み込み(indexを指定しない) import pandas as pd df3 = pd.read_excel('sample.xlsx', sheet_name='Sheet1' ,index_col=0) print(df3.head()) |
print(df3.head())
printで表示すると、以下のようになります。
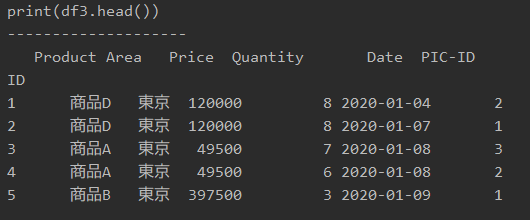
「index_col = 0」とすると、上記の画像のとおりindexが表示されなくなります。
Pandasにおけるindexとは?
indexとは以下の画像の、赤枠で囲んだ部分です。(以下の画像はプログラム1のものです)
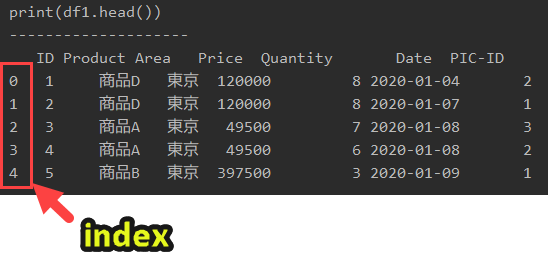
indexが不要の場合は、「index_col = 0」とします。
プログラム4|データがないセル(NaN)を他の値で埋める
|
1 |
#プログラム4|エクセルをpandasで読み込み(indexを指定しない) |
Pandasでエクセルのsum関数・count関数を実行
プログラム5|Pandasでエクセルのcount関数
プログラム6|Pandasでエクセルのsum関数
エクセル関数のcount関数やsum関数の処理をPandasで処理する場合を紹介します。
プログラム5|Pandasでエクセルのcount関数
|
1 2 3 4 5 |
#プログラム5|Pandasでエクセル関数count import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df5_count = df['Price'].count() print(df5_count) |
プログラム解説
上記のプログラムで、「Price」列の含まれるデータの件数(個数)をカウントすることができます。
printで表示すると、以下のようになります。

プログラム6|Pandasでエクセルのsum関数
|
1 2 3 4 5 |
#プログラム6|Pandasでエクセル関数sum import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df6_sum = df['Price'].sum() print(df6_sum) |
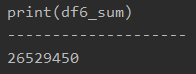
上記のプログラムで、「Price」列の含まれるデータの合計値を算出することができます。
printで表示すると、以下のようになります。
Pandasで条件に合致したデータの件数・合計|countif、sumif
プログラム7|Pandasでエクセルのcountif関数
|
1 2 3 4 5 6 |
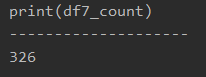
import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') product1 = '商品A' df7 = df[df['Product'] == product1] df7_count = df7['Price'].count() print(df7_count) |
プログラム解説
df7 = df[df[‘Product’] == product1]
df7_count = df7[‘Price’].count()
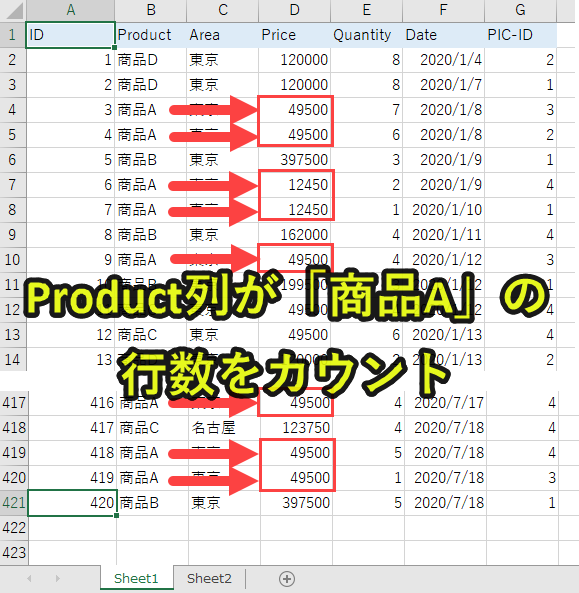
「Product」列のデータの中で、「product1(商品A)」に合致するデータをdf7として取得します。
「df7[‘Price’].count()」でデータ数をカウントします。
printで表示すると、以下のようになります。
プログラム8|Pandasでエクセルのsumif関数
|
1 2 3 4 5 6 |
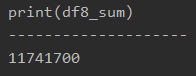
import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') product1 = '商品A' df8 = df[df['Product'] == product1] df8_sum = df8['Price'].sum() print(df8_sum) |
プログラム解説
df8 = df[df[‘Product’] == product1]
df8_sum = df8[‘Price’].sum()
「Product」列のデータの中で、「product1(商品A)」に合致するデータをdf8として取得します。
「df8[‘Price’].sum()」でデータの合計値を算出します。

printで表示すると、以下のようになります。
プログラム9|Pandasでエクセルsumif関数で出来ない2条件抽出
|
1 2 3 4 5 6 7 8 9 |
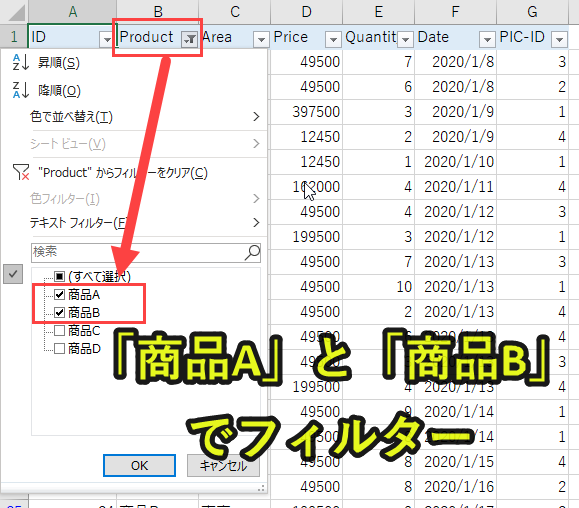
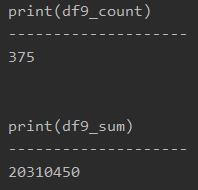
import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') product1 = '商品A' product2 = '商品B' df9 = df[(df['Product'] == product1)|(df['Product'] == product2)] df9_count = df9['Price'].count() df9_sum = df9['Price'].sum() print(df9_count) print(df9_sum) |
プログラム解説
product2 = ‘商品B’
df9 = df[(df[‘Product’] == product1)|(df[‘Product’] == product2)]
「Product」列のデータの中で、「product1(商品A)」または「product2(商品B)」に合致するデータをdf9として取得します。
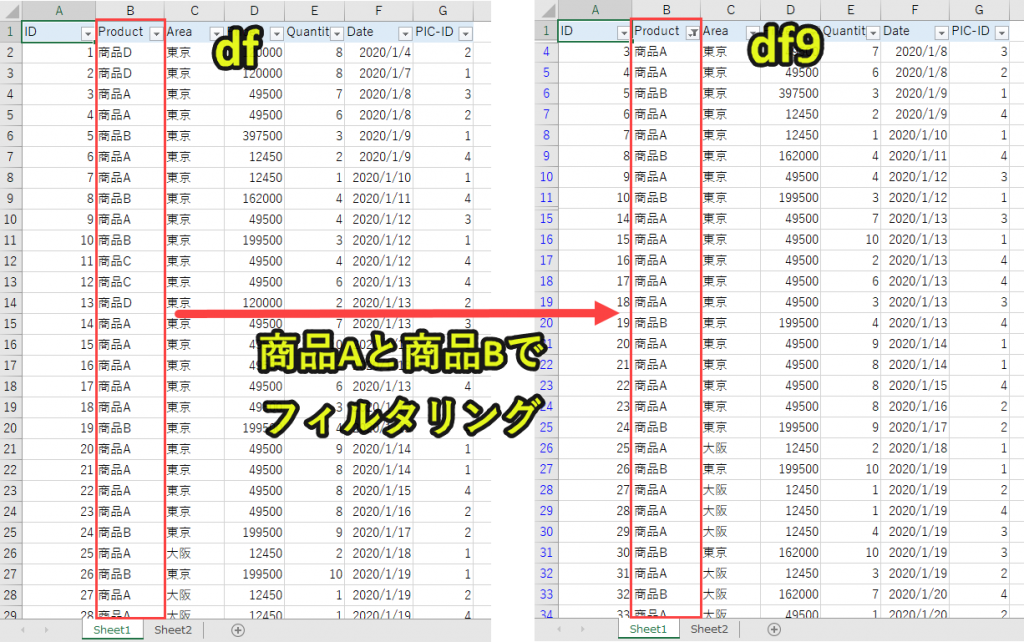
Excelの機能で言えば、「Product」列を2つの条件でフィルターしている状態をイメージすると分かりやすいです。
df9_sum = df9[‘Price’].sum()
print(df9_count)
print(df9_sum)
printで表示すると、以下のようになります。
プログラム10|Pandasで条件以外のデータを抽出(エクセルsumif関数で出来ない)
|
1 2 3 4 5 6 7 8 9 |
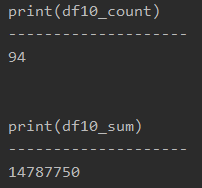
#プログラム10|Pandasで条件以外のデータを抽出(エクセルsumif関数で出来ない) import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') product1 = '商品A' df10 = df[df['Product'] != product1] df10_count = df10['Price'].count() df10_sum = df10['Price'].sum() print(df10_count) print(df10_sum) |
プログラム解説
df10 = df[df[‘Product’] != product1]
「Product」列のデータの中で、「product1(商品A)」ではないデータをdf10として取得します。
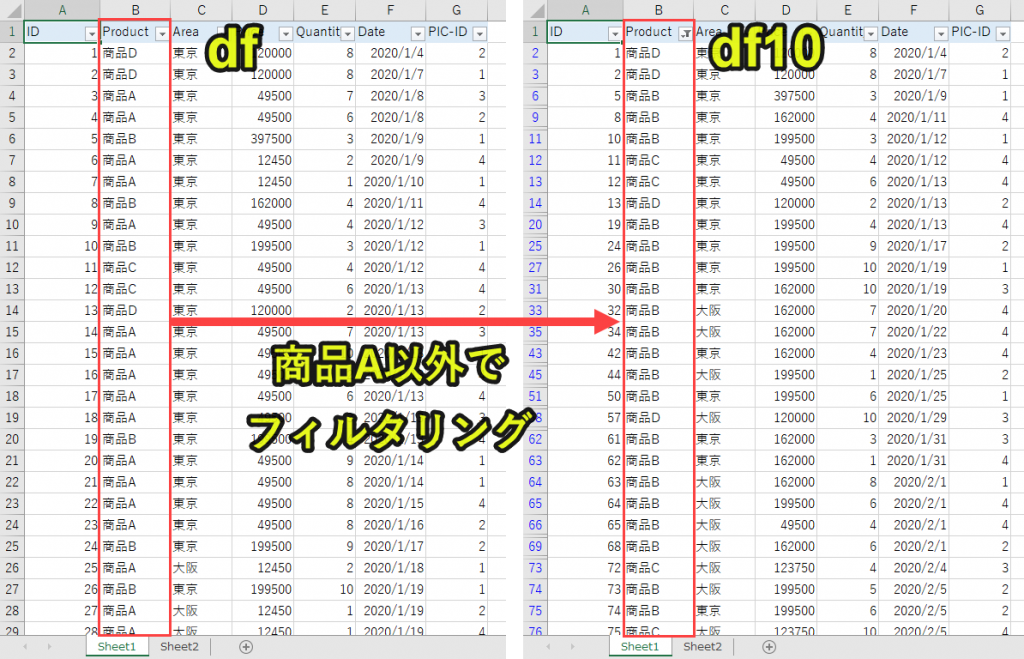
「df[‘X’] != Y 」で「X列のYではない値のみを抽出」することができます。
Excelの機能で言えば、「Product」列で「商品A」以外の要素に全てチェックが入っている状態をイメージすると分かりやすいです。
df10_sum = df10[‘Price’].sum()
print(df10_count)
print(df10_sum)
printで表示すると、以下のようになります。
Pandasで特定の文字列を含んでいる行の件数・合計|countif、sumifではできない
プログラム11|Pandasで特定の文字列を含んでいるセルのみ抽出
|
1 2 3 4 5 6 7 |
import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df11 = df[df['Product'].str.contains('A',na=False)] df11_count = df11['Price'].count() df11_sum = df11['Price'].sum() print(df11_count) print(df11_sum) |
プログラム12|Pandasで特定の文字列を含んでいるセルのみ抽出
|
1 2 3 4 5 6 7 |
import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df12 = df[df['Product'].str.contains('A' or 'B',na=False)] df12_count = df12['Price'].count() df12_sum = df12['Price'].sum() print(df12_count) print(df12_sum) |
Pandasで複数条件に合致したデータの件数・合計|countifs、sumifs
プログラム13|Pandasでエクセルのcountifs関数
|
1 2 3 4 5 6 7 8 |
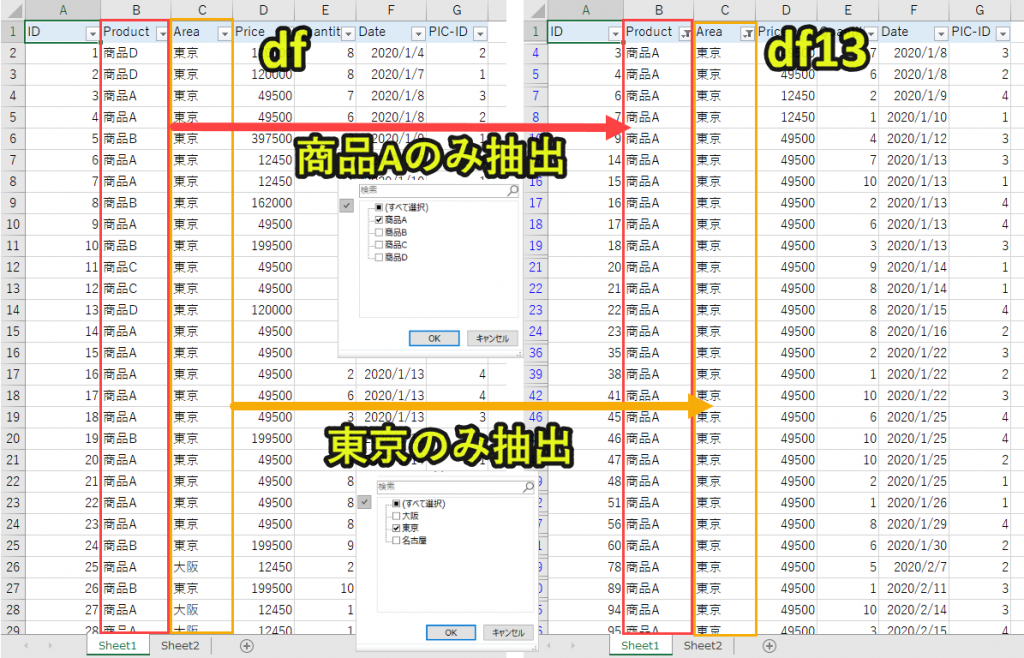
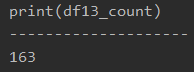
#プログラム13|Pandasでエクセルのcountifs関数 import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') product = '商品A' area = '東京' df13 = df[(df['Product'] == product)&(df['Area'] == area)] df13_count = df13['Price'].count() print(df13_count) |
プログラム解説
area = ‘東京’
df13 = df[(df[‘Product’] == product)&(df[‘Area’] == area)]
・「Area」列のデータの中で、「area(東京)」
上記の2つを両方を満たすデータをdf13として取得します。
「(df[‘X1’] == Y1 & df[‘X2’] == Y2) 」で「X1列のY1」かつ「X2列のY2」に合致する値のみを抽出することができます。
print(df13_count)
printで表示すると、以下のようになります。
プログラム14|Pandasでエクセルのsumifs関数
|
1 2 3 4 5 6 7 8 |
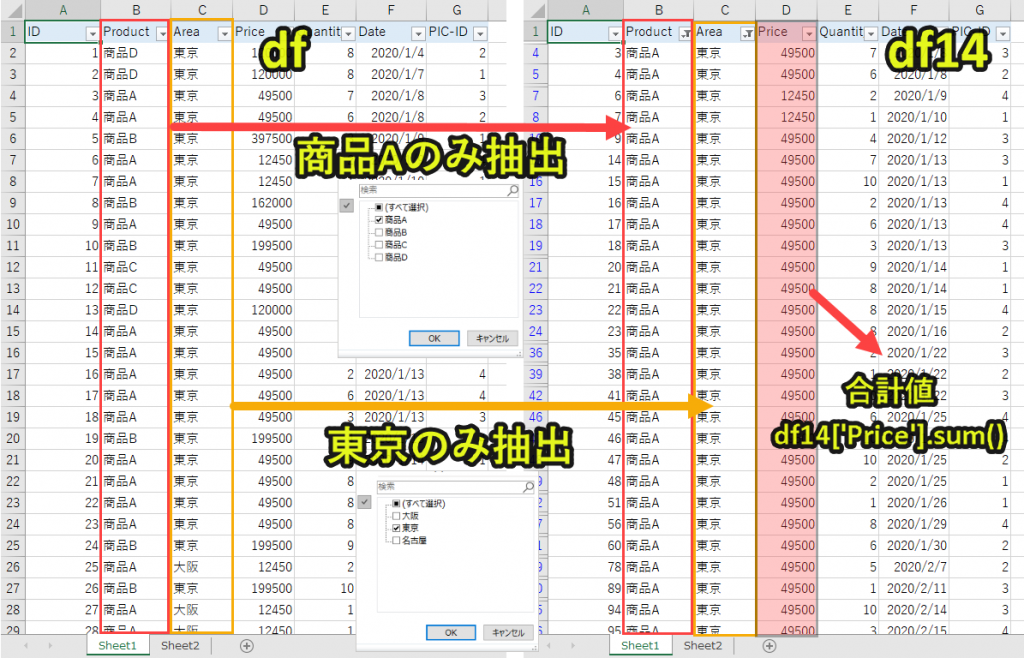
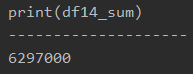
#プログラム14|Pandasでエクセルのsumifs関数 import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') product = '商品A' area = '東京' df14 = df[(df['Product'] == product)&(df['Area'] == area)] df14_sum = df14['Price'].sum() print(df14_sum) |
プログラム解説
area = ‘東京’
df14 = df[(df[‘Product’] == product)&(df[‘Area’] == area)]
・「Area」列のデータの中で、「area(東京)」
上記の2つを両方を満たすデータをdf14として取得します。
print(df14_sum)
printで表示すると、以下のようになります。
プログラム15|Pandasで2つの列を複数条件で抽出(エクセルのcountifsやsumifs関数で出来ない)
|
1 2 3 4 5 6 7 8 9 10 11 |
import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') product1 = '商品A' area1 = '東京' area2 = '大阪' df15_1 = df[df['Product'] == product1] df15_2 = df15_1[(df15_1['Area'] == area1)|(df15_1['Area'] == area2)] df15_2_count = df15_2['Price'].count() df15_2_sum = df15_2['Price'].sum() print(df15_2_count) print(df15_2_sum) |
プログラム解説
area1 = ‘東京’
area2 = ‘大阪’
df15_1 = df[df[‘Product’] == product1]
df15_2 = df15_1[(df15_1[‘Area’] == area1)|(df15_1[‘Area’] == area2)]
ステップ2. df15_1に対して、「Area」列が「area1(東京)」もしくは「area2(大阪)」を抽出したデータをdf15_2とする
上記のように2ステップに分けて、データを抽出していくと分かりやすいです。
print(df15_count)
df15_sum = df15[‘Price’].sum()
print(df15_sum)
printで表示すると、以下のようになります。
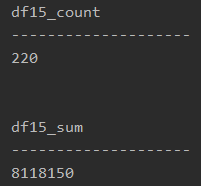
Pandasでsumproduct関数
プログラム16|Pandasでエクセルのsumproduct関数
|
1 2 3 4 5 6 |
#プログラム16|sumproduct import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df['Sumproduct1'] = df['Price']*df['Quantity'] df16_sum = df['Sumproduct1'].sum() print(df16_sum) |
プログラム解説
新しく作成したdf[‘Sumproduct’]という列にdf[‘Price’]とdf[‘Quantity’]の積(掛け算の結果)を出力します。
ちなみにエクセル上では、以下をイメージすると分かりやすいです。
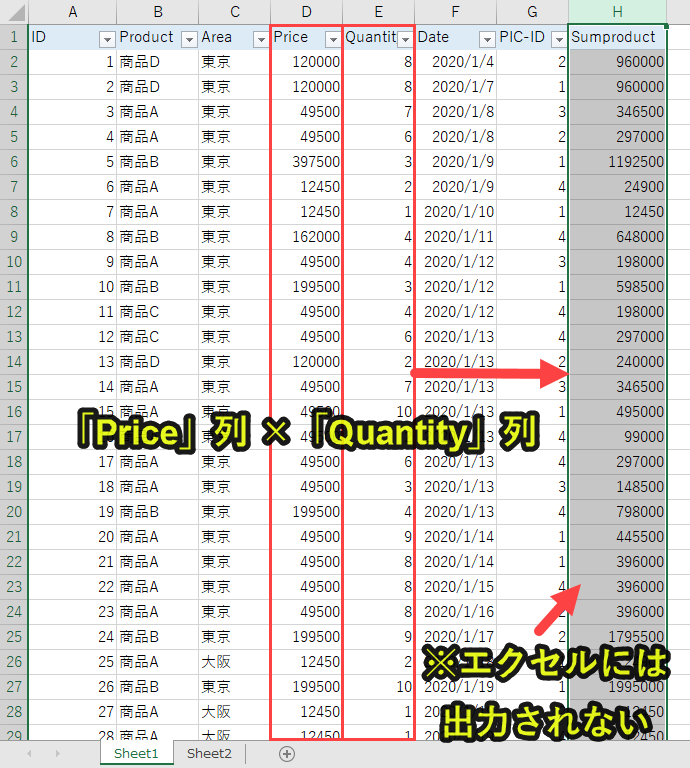
ただし、「Sumprodcut」列が出力されるわけではありません。Python上でdf[‘Sumproduct1’]として計算されるだけです。
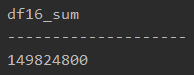
print(df16_sum)
「df[‘Sumproduct1’].sum()」で、df[‘Sumproduct1’]の合計値を算出することができます。
printで表示すると、以下のようになります。
プログラム17|Pandasでエクセルのsumproduct関数
|
1 2 3 4 5 6 7 8 9 |
#プログラム17|sumproduct import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') product = '商品A' area = '東京' df17 = df[(df['Product'] == product)&(df['Area'] == area)].copy() df17['Sumproduct2'] = df17['Price']*df17['Quantity'] df17_sum = df17['Sumproduct2'].sum() print(df17_sum) |
プログラム解説
area = ‘東京’
df17 = df[(df[‘Product’] == product)&(df[‘Area’] == area)].copy()
これは、プログラム13とプログラム14とほぼ同じです。
復習を兼ねて、以下でカンタンに説明をします。
・「Area」列のデータの中で、「area(東京)」
上記の2つを両方を満たすデータをdf17として取得します。
最後に「.copy()」としていますが、これは「.copy()」としないと警告が出るからです。
その回避方法としては「.copy()」を入れています。
df17はdf(もともとのDataFrame)dfを処理したView状態です。View状態のまま処理をするとエラーが出るので、「.copy()」とすることで、ViewをDataFrameに書き換えを行っているという意味です。
分かりづらいかもしれませんので、ここは読み飛ばしていただいて問題ありません。要はエラー回避のために「.copy()」を入れています。
新しく作成したdf17[‘Sumproduct2’]という列にdf17[‘Price’]とdf17[‘Quantity’]の積(掛け算の結果)を出力します。
print(df17_sum)
「df17[‘Sumproduct2’].sum()」で、df17[‘Sumproduct2’]の合計値を算出することができます。
printで表示すると、以下のようになります。

Pandasでvlookup関数
プログラム18|Pandasでエクセルのvlookup関数
今回やりたいことは以下です。
・「PIC-Name」の値はSheet1のPIC-IDをキーにしてSheet2から参照させたい
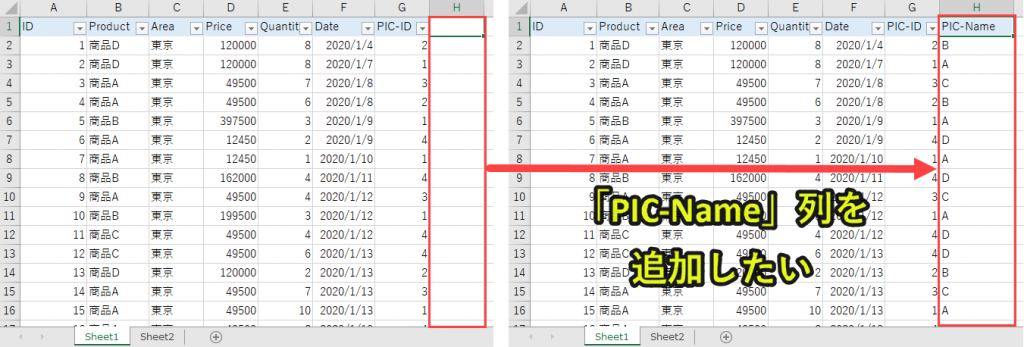
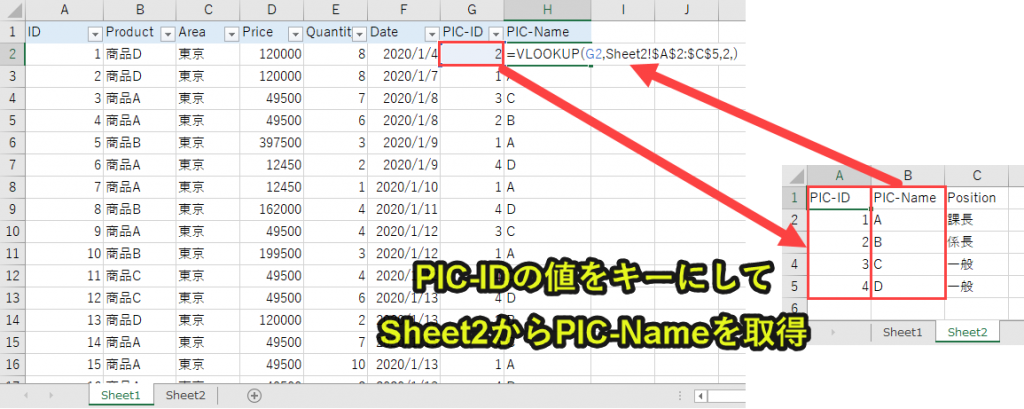
要はエクセルのvlookup関数で、Sheet2の値を参照するのと同じことをしたいわけです。
ちなみに「vlookup(G2,Sheet2!$A$2:$C$5,2, False)」と記載します。
これをPandasで実行するためには、以下のプログラムで実現できます。
|
1 2 3 4 5 6 7 |
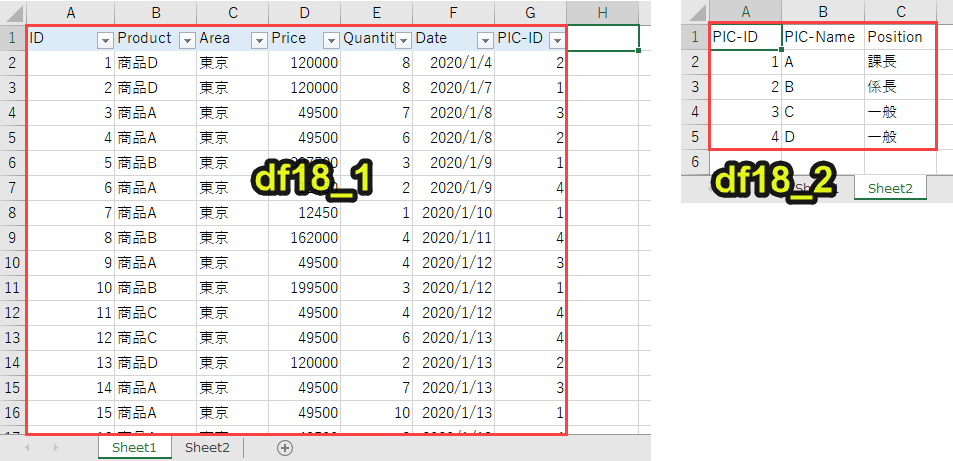
#プログラム18|vlookup import pandas as pd df18_1 = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df18_2 = pd.read_excel('sample.xlsx', sheet_name='Sheet2') dict = dict(zip(df18_2['PIC-ID'], df18_2['PIC-Name'])) df18_1['PIC-Name'] = df18_1['PIC-ID'].map(dict) print(df18_1.head()) |
プログラム解説
df18_2 = pd.read_excel(‘sample.xlsx’, sheet_name=’Sheet2′)
Sheet1とSheet2をそれぞれdf18_1とdf18_2として読み込みます。
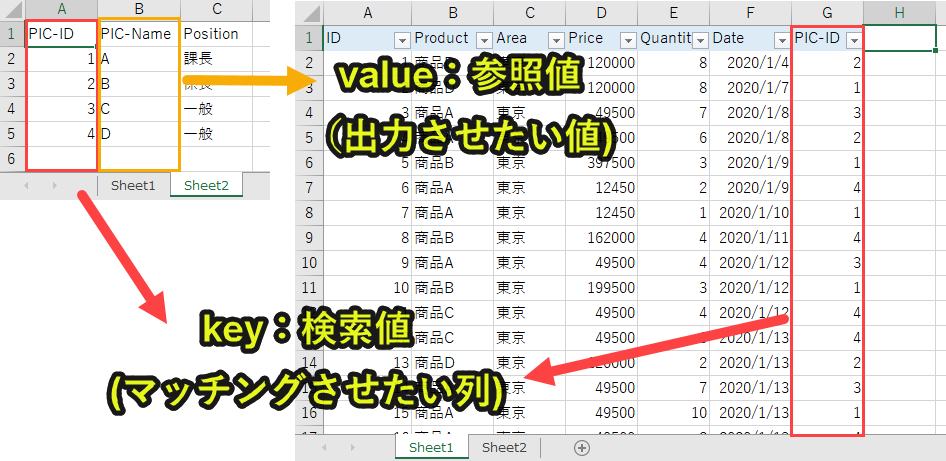
Sheet2のデータをzip(key, value)で辞書を作成します。
・「value」に参照値となる列 → 今回の事例では「PIC-Name」
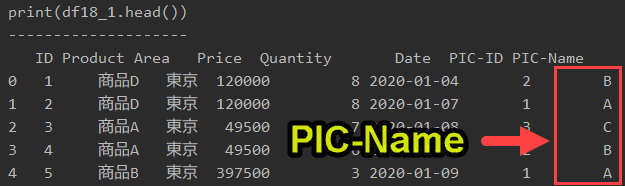
print(df18_1.head())
これで、df18_1に「PIC-Name」列を作成し、Sheet2の「PIC-Name」を参照して値を出力します。
「print(df18_1.head())」で表示すると、以下のようになります。
補足
なお、print(dict)とすると、以下のようになります。
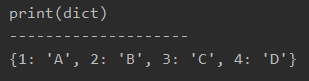
このように、zip(key, value)に検索値と参照値の列を入力することで、vlookupのような挙動をPandasで実現可能です。
Pandasピボットテーブル
プログラム19|ピボットテーブルで製品とエリアをクロス集計
|
1 2 3 4 5 |
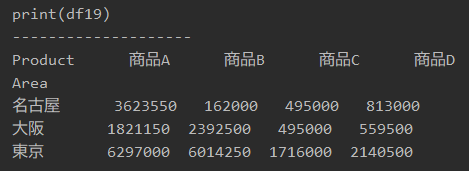
#プログラム19|ピボットテーブルで製品とエリアをクロス集計 import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df19 = pd.pivot_table(df, index='Area', columns='Product', values='Price', aggfunc='sum') print(df19) |
プログラム解説
print(df19)
・columns= ‘Product’ →ピボットテーブルの列に入力する列|今回は「Product」列
・value = ‘Price’ →ピボットテーブルで計算したい列|今回は「Price」列
・aggfunc = ‘sum’ →valueの計算方法|値をとして出力
「print(df19)」で表示すると、以下のようになります。
プログラム20|ピボットテーブルで月ごと
|
1 2 3 4 5 6 |
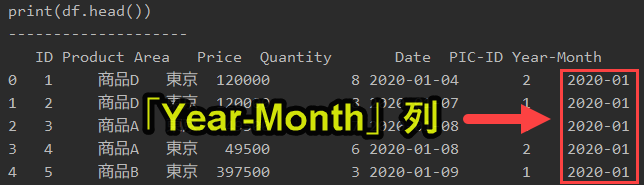
#プログラム20|月別と製品別の各要素の合計値をピボットテーブルで計算 import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df['Year-Month'] = pd.to_datetime(df['Date']).dt.strftime("%Y-%m") df20 = pd.pivot_table(df, index='Year-Month', columns='Product', values='Price', aggfunc='sum') print(df20) |
プログラム解説
上記のプログラムは、df[‘Year-Month’]という列を作成し、そこにdf[‘Date’]の日付から「YYYY-mm」部分を取り出して、df[‘Year-Month’]に格納します。
文章だけの説明だとわかりにくいので、print(df.head())で出力してみます。
すると、以下のようになります。
・columns= ‘Product’ →ピボットテーブルの列に入力する列|今回は「Product」列
・value = ‘Price’ →ピボットテーブルで計算したい列|今回は「Price」列
・aggfunc = ‘sum’ →valueの計算方法|値をとして出力
「print(df20)」で表示すると、以下のようになります。
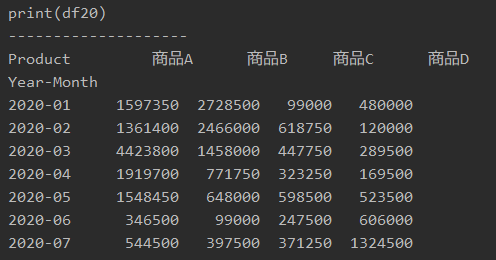
プログラム21|ピボットテーブルで四半期ごと
|
1 2 3 4 5 6 7 8 |
#プログラム21|ピボットテーブルで四半期ごと import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df['Quarter'] = pd.to_datetime(df['Date']).dt.quarter df['Year'] = pd.to_datetime(df['Date']).dt.year df['Year-Quarter'] = df['Year'].astype(str).str.cat(df['Quarter'].astype(str), sep='-') + 'Q' df21 = pd.pivot_table(df, index='Year-Quarter', columns='Product', values='Price', aggfunc='sum') print(df21) |
プログラム解説
df[‘Year’] = pd.to_datetime(df[‘Date’]).dt.year
df[‘Year-Quarter’] = df[‘Year’].astype(str).str.cat(df[‘Quarter’].astype(str), sep=’-‘) + ‘Q’
この3行で、df[‘Year-Quarter’]列に「YYYY-1Q」、「YYYY-2Q」、「YYYY-3Q」、「YYYY-4Q」を入れ込んでいきます。
具体的には以下のステップで行います。
2. df[‘Year’]を作成し、「YYYY(年)」を取得
3. df[‘Year-Quarter’]を作成し、df[‘Year’] + df[‘Quarter’] + 「Q」を文字列で結合
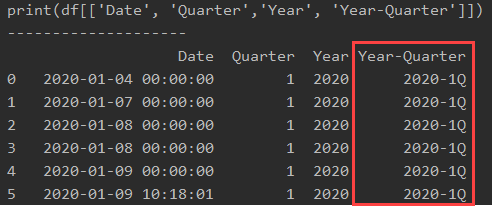
上記の文章だけの説明だとわかりにくいので、「Date」,「Quarter」,「Year」,「Year-Quarter」の列のみをprintで出力してみます。
以下のプログラムで、特定の列のみを出力することができます。
すると、以下のような結果が得られました。
・index= ‘Year-Quarter’ →ピボットテーブルの行に入力する列|今回は「Year-Quarter」列
・columns= ‘Product’ →ピボットテーブルの列に入力する列|今回は「Product」列
・value = ‘Price’ →ピボットテーブルで計算したい列|今回は「Price」列
・aggfunc = ‘sum’ →valueの計算方法|値をとして出力
得られた[Year-Quarter]を行(index)としてピボットテーブルを作成します。
「print(df21)」で表示すると、以下のようになります。
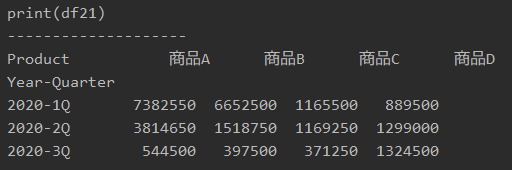
プログラム22|ピボットテーブルで週ごと
|
1 2 3 4 5 6 7 8 9 10 |
#プログラム22|ピボットテーブルで週ごと import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df['myday'] = pd.to_datetime(df['Date']) df['daysoffset'] = df['myday'].apply(lambda x: x.weekday()) from datetime import timedelta df['week_start'] = df.apply(lambda x: x['myday'] - timedelta(days=x['daysoffset']), axis=1) df['week_start'] = pd.to_datetime(df['week_start']).dt.strftime("%Y-%m-%d") df22 = pd.pivot_table(df, index='week_start', columns='Product', values='Price', aggfunc='sum', fill_value=0) print(df22) |
プログラム解説
全体の流れは以下のとおりです。
2. 「daysoffset」で曜日を数値として取得
3. 「week_start」=「myday」 – 「daysoffset」とすることで、その日付の月曜日を取得
4. 「week_start」(その日付の週の月曜日)をもとにピボットテーブルを作成
それでは以下で詳しく解説しています。
df[‘daysoffset’] = df[‘myday’].apply(lambda x: x.weekday())
1行で「Date」列の日付をdatetime型に変換します。これでdatetimeとして計算できるようになります。
2行で、weekdayの数値に変換して、その値を「dayoffset」という列に格納します。
weekdayは、数値と曜日を以下のように紐づけています。
1:火
2:水
3:木
4:金
5:土
6:日
上記の文章だけの説明だとわかりにくいので、「Date」列と「dayoffset」列をprintで出力してみます。
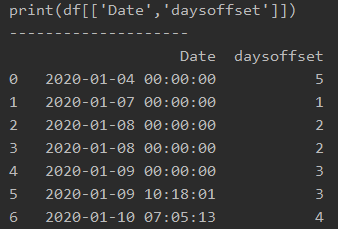
df[‘week_start’] = df.apply(lambda x: x[‘myday’] – timedelta(days=x[‘daysoffset’]), axis=1)
df[‘week_start’] = pd.to_datetime(df[‘week_start’]).dt.strftime(“%Y-%m-%d”)
1行目で「timedelta」を呼び出して、2行目で日付の差分計算できるようにします。
2行目で「myday」列の日付 - 「daysoffset」の数値(曜日と連動した数値)として、月曜日の日付を取得します。
3行目でstrftimeを使って「YYYY-mm-dd」型に変換します
上記の文章だけの説明だとわかりにくいので、「Date」列と「week_start」列をprintで出力してみます。
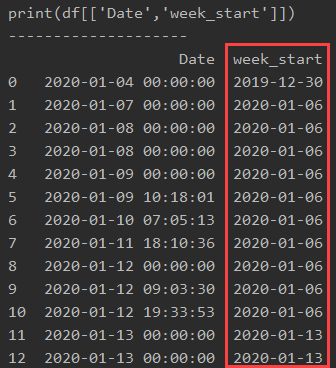
これで、その日付が含まれる月曜日を取得できました。
・index= ‘week_start’ →ピボットテーブルの行に入力する列|今回は「week_start」列
・columns= ‘Product’ →ピボットテーブルの列に入力する列|今回は「Product」列
・value = ‘Price’ →ピボットテーブルで計算したい列|今回は「Price」列
・aggfunc = ‘sum’ →valueの計算方法|値をとして出力
・fill_value = 0 →NaNの値の代わりに「0」を入力
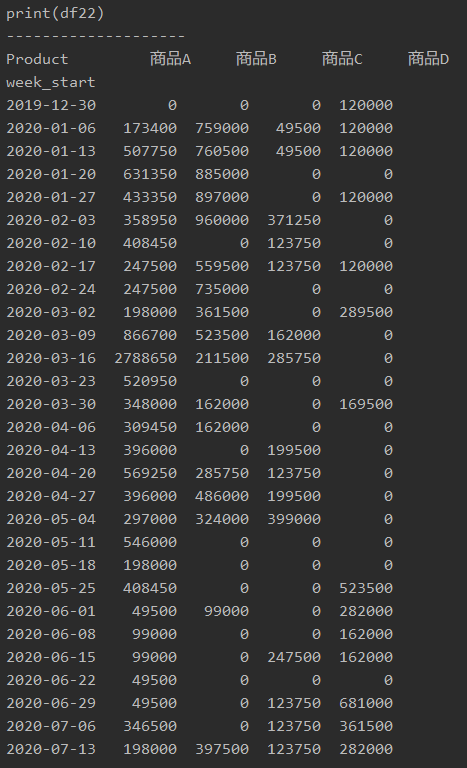
得られた[week_start]を行(index)としてピボットテーブルを作成します。
「print(df22)」で表示すると、以下のようになります。
補足
上記で「fill_value = 0」なしで出力すると、以下のように「NaN」が出力されます。
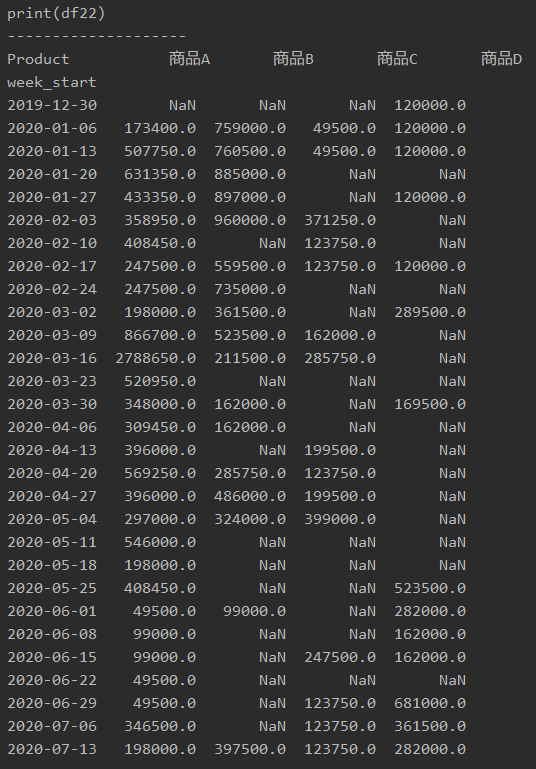
そのため、「fill_value = 0」を入れる方があとあとの計算がラクになります。
Pandasで重複を削除
|
1 2 3 4 |
#データを削除するときはdrop_duplicates import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df23 = df.drop_duplicates() |
プログラム解説
上記のプログラムで重複を削除することができます。
()内で明示しなければ、最初に出現する値を残します。
補足
(keep=’last’)と明示することで、最後に出現する値を残します。
またここでは記載していませんが、列を指定して重複を削除することも可能です。
列内の全要素を抽出
プログラム24|列の全要素を抽出
|
1 2 3 4 5 6 7 |
import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df24 = df.groupby('Product') df24_count = df24.count()['Price'] print(df24_count) df24_sum = df24.sum()['Price'] print(df24_sum) |
プログラム解説
groupbyを使うことで、特定の列に含まれる全要素について要素ごとにデータを取得することができます。
print(df24_count)
df24_sum = df24.sum()[‘Price’]
print(df24_sum)
「print(df24_count)とprint(df24_sum)」で表示すると、以下のようになります。
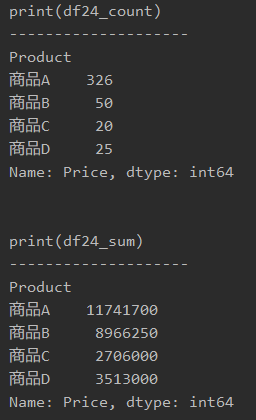
このような機能はエクセルには存在しないので、とても便利です。
プログラム25|特定の列の全要素を抽出
|
1 2 3 4 5 6 7 8 |
#プログラム25|特定の列の全要素を抽出 import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df25 = df.groupby(['Product', 'Area']) df25_count = df25.count()['Price'] print(df25_count) df25_sum = df25.sum()['Price'] print(df25_sum) |
プログラム解説
「Product」列と「Area」列の2つでデータをgroupbyで取得します。
これで、この2つの列に含まれる全要素について要素ごとにデータを取得することができます。
print(df25_count)
df25_sum = df25.sum()[‘Price’]
print(df25_sum)
「print(df25_count)とprint(df25_sum)」で表示すると、以下のようになります。
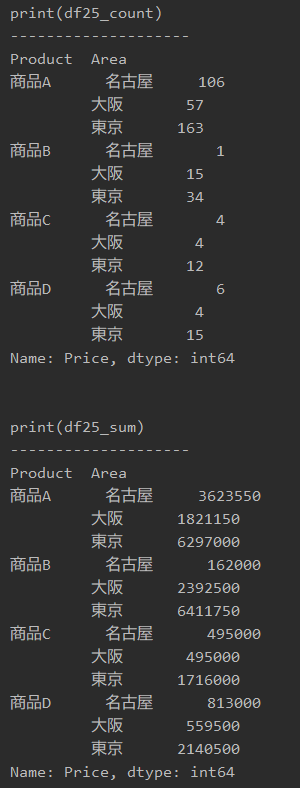
短いプログラムで、データの全容をカンタンに把握できるのが、groupbyのメリットです。
このような機能はエクセルには存在しないので、覚えておくと便利です。
Pandasでエクセルを書き出して保存する
プログラム26|エクセルを保存する
|
1 2 3 4 5 6 7 |
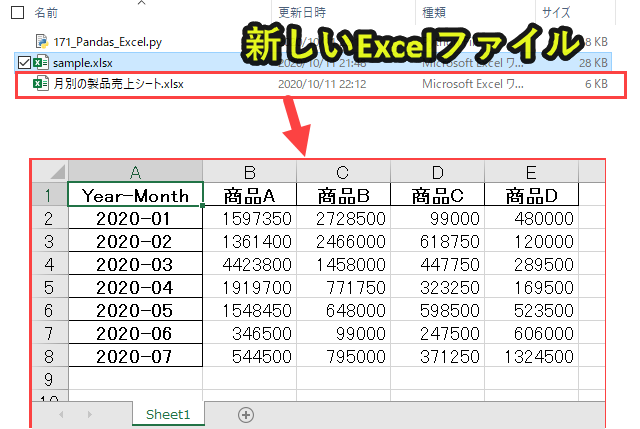
#プログラム26|エクセルを保存する import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df['Year-Month'] = pd.to_datetime(df['Date']).dt.strftime("%Y-%m") df26 = pd.pivot_table(df, index=['Year-Month'], columns='Product', values='Price', aggfunc='sum') filepath = '月別の製品売上シート.xlsx' df26.to_excel(filepath) |
プログラム解説
df26 = pd.pivot_table(df, index=[‘Year-Month’], columns=’Product’, values=’Price’, aggfunc=’sum’)
ここまではプログラム20(月別の製品ごとのピボットテーブル作成)と同じです。
このピボットテーブルを別のエクセルファイルとして出力します。
df26.to_excel(filepath)
1行目で、filepathを指定します。出力したいピボットテーブルのファイル名を入力します。
2行目で、エクセルファイルを出力します。
プログラム27|エクセルをシート名を指定して保存する
|
1 2 3 4 5 6 7 |
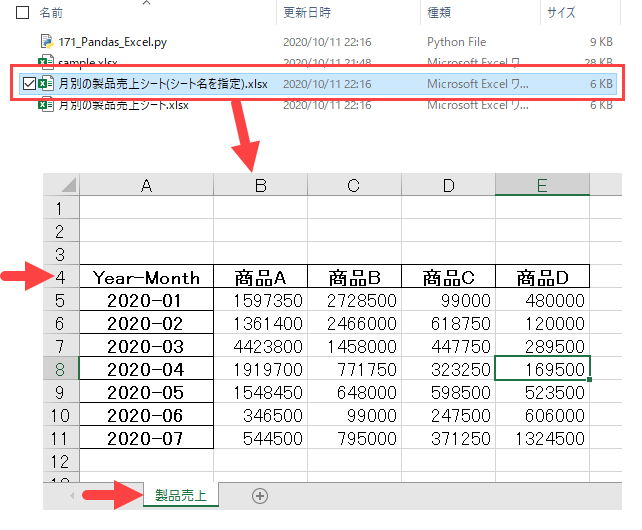
#プログラム27|エクセルをシート名を指定して保存する import pandas as pd df = pd.read_excel('sample.xlsx', sheet_name='Sheet1') df['Year-Month'] = pd.to_datetime(df['Date']).dt.strftime("%Y-%m") df27 = pd.pivot_table(df, index=['Year-Month'], columns='Product', values='Price', aggfunc='sum') filepath = '月別の製品売上シート(シート名を指定).xlsx' df27.to_excel(filepath, sheet_name='製品売上', startrow=3) |
プログラム解説
df27 = pd.pivot_table(df, index=[‘Year-Month’], columns=’Product’, values=’Price’, aggfunc=’sum’)
ここまではプログラム20(月別の製品ごとのピボットテーブル作成)と同じです。
このピボットテーブルを別のエクセルファイルとして出力します。
df27.to_excel(filepath, sheet_name=’製品売上’, startrow=3)
1行目で、filepathを指定します。出力したいピボットテーブルのファイル名を入力します。
2行目で、エクセルファイルを出力します。このとき「sheet_name=’製品売上’」でシート名を指定し、「startrow=3」で開始行を4行目に指定することができます。
プログラムの解説はここまでです。
Pythonについて詳しく理解したいなら
Pythonを活用すると、仕事を効率化できる幅を広げることができます。
たとえば私が実際にPythonを活用して効率化してきた作業は以下の記事で紹介しています。
興味がある人は以下の記事もご覧ください。

Pythonの難易度などについては、以下で紹介しています。

勉強の参考になれば幸いです。