
Pythonを使うとPDFをまとめて結合することができます。
ここでは実務の事例として、複数のPDFを一つに集約するPythonプログラムを紹介します。
この記事では以下についてお伝えしていきます。
・必要なライブラリ
それでは以下で詳しく紹介していきます。
目次
Pythonで複数PDFを読み込み、1つに結合する
今回は以下の作業をpythonで行います。
1. フォルダ内のPDFを全て読み込む
2. 順番とおりにPDFを結合
まず、フォルダ内のPDFを全て読み込みます。
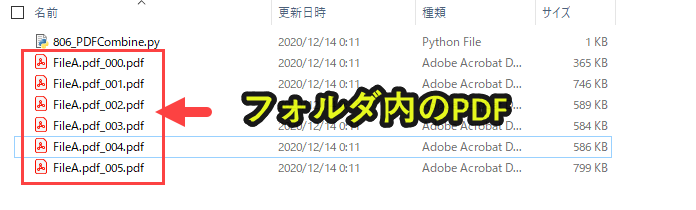
Pythonプログラムで全てのPDFを読み込み、結合します。
最終的に新しいPDFを作成し、同じフォルダに保存します。
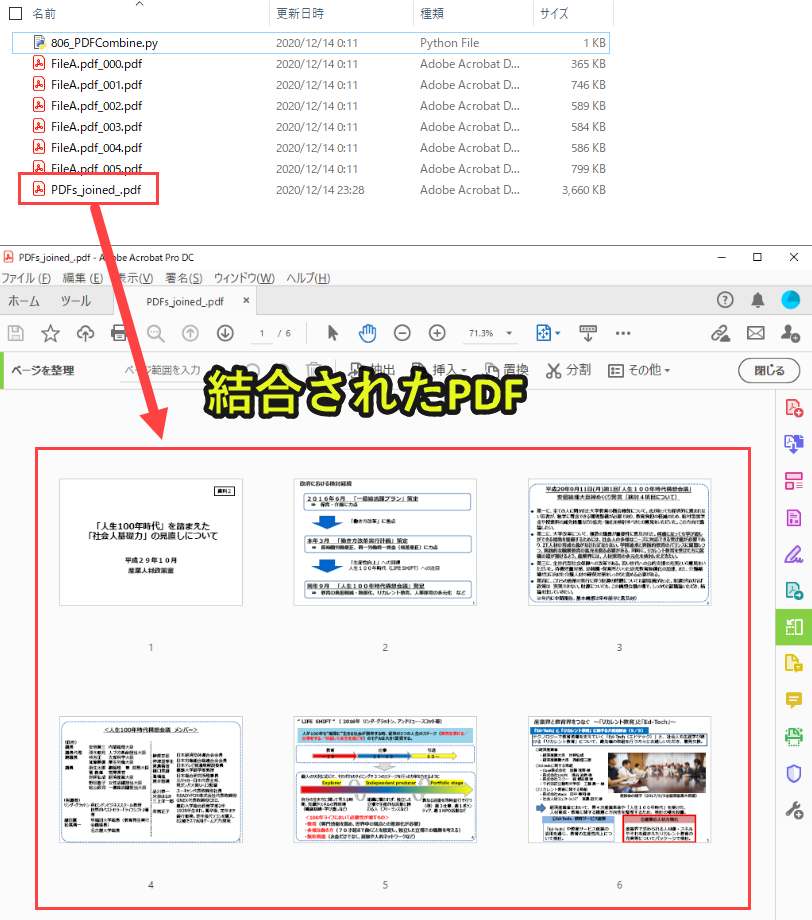
上記のように、複数のPDFを一つのPDFに集約します。
Pythonプログラムを実行するための準備|PDF保存とライブラリ
1. 結合したいPDFをフォルダに保存(「.py」と同じフォルダ)
2. 必要なライブラリをインストール
準備1|結合したいPDFをフォルダに保存(「.py」と同じフォルダ)
結合したいPDFをフォルダに保存します。
Pythonファイル「.py」と同じフォルダにPDFを保存すること
後半で紹介するプログラムをそのまま使用する場合は、「.py」と「.pdf」が同じフォルダでないとエラーが発生します。
フォルダを指定したい場合は、本記事で紹介するプログラムを一部変更する必要がありますので、ご注意ください。
準備2|必要なライブラリをインストール
今回は以下の2つのライブラリをインストールします。
pip install pymupdf
PDFのテキストを取得するためのライブラリです。
上記をインストールしておかないと動かないので、注意が必要です。
PyPDF2でなくても結合可能か?
本プログラムでは、PyPDF2ではなくPymupdfというライブラリを使用しています。
どちらでもファイルの結合は可能です。
本記事でPymupdfによるPDF結合を紹介している理由は、他であまり紹介されていないからです。
Pymupdfは日本語のテキストを取得することもできるスグレモノです。
この機会にぜひ知っておいていただきたいと考え、PymupdfによるPDF結合プログラムを紹介しています。
Pythonプログラム解説
この記事で紹介するプログラムを解説しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# プログラム1|ライブラリ設定 import fitz import pathlib import os # プログラム2|結合したい(結合元)PDFを取得 curdir = os.getcwd() files = list(pathlib.Path(curdir).glob('*.pdf')) # プログラム3|結合元PDFを並び替え sfiles = sorted(files) # プログラム4|結合先のPDFを新規作成 doc = fitz.open() # プログラム5|結合元PDFを開く for file in sfiles: infile = fitz.open(file) # プログラム6|結合先PDFと結合元PDFのページ番号を指定 doc_lastPage = len(doc) infile_lastPage = len(infile) doc.insertPDF(infile, from_page=0, to_page=infile_lastPage, start_at=doc_lastPage, rotate=0) # プログラム7|結合元PDFを閉じる infile.close() # プログラム8|結合先PDFを保存する filename = 'PDFs_joined_.pdf' doc.save(filename) |
以下で詳しく説明しています。
プログラム1|ライブラリの設定
|
1 2 3 4 |
# プログラム1|ライブラリ設定 import fitz import pathlib import os |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
import fitz |
fitzはこのライブラリでPDFのテキストを取得します。(pymupdfのライブラリ)
|
3 |
import pathlib |
pathlibはフォルダ内の全PDFを取得するときに使います。
|
4 |
import os |
osはフォルダ指定で使います。
プログラム2|結合したい(結合元)PDFを取得
|
1 2 3 |
# プログラム2|結合したい(結合元)PDFを取得 curdir = os.getcwd() files = list(pathlib.Path(curdir).glob('*.pdf')) |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
curdir = os.getcwd() |
「.py」ファイルが保管されているフォルダをcurdirとして取得します。
|
1 2 |
curdir = os.getcwd() print(curdir) |
実行結果
|
1 |
>>>D:\DropBox\Dropbox\Python\Program\800_PDF\806_PDF_Combine |
「os.getcwd()」で「.py」ファイルが保管されているフォルダを取得できます。
|
3 |
files = list(pathlib.Path(curdir).glob('*.pdf')) |
curdirのフォルダ内で、拡張子が「.pdf」のファイルをfilesとして取得します。
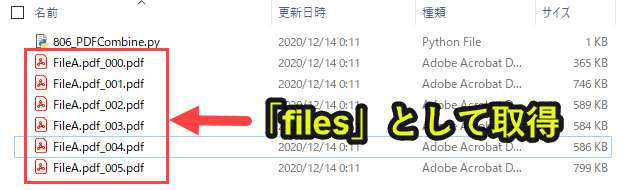
|
1 2 |
files = list(pathlib.Path(curdir).glob('*.pdf')) [print(file) for file in files] |
実行結果
|
1 2 3 4 5 6 |
>>>D:\DropBox\Dropbox\Python\Program\800_PDF\806_PDF_Combine\FileA.pdf_000.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\806_PDF_Combine\FileA.pdf_001.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\806_PDF_Combine\FileA.pdf_002.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\806_PDF_Combine\FileA.pdf_003.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\806_PDF_Combine\FileA.pdf_004.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\806_PDF_Combine\FileA.pdf_005.pdf |
「files」で「.py」ファイルが保管されているフォルダ内の「.pdf」を全て取得できます。
なお、フルパスで取得します。
プログラム3|結合元PDFを並び替え
|
1 2 |
# プログラム3|結合元PDFを並び替え sfiles = sorted(files) |
files(プログラム2)をsortedで並び替えます。
順番に並び替えることで、プログラム5以降で結合する順番をコントロールします。
ただし並び替えには注意が必要です。
プログラム
|
1 2 3 |
files=['1.pdf','2.pdf','3.pdf','4.pdf','5.pdf','6.pdf','7.pdf','8.pdf','9.pdf','10.pdf','11.pdf'] sfiles = sorted(files) [print(sfile) for sfile in sfiles] |
実行結果
|
1 2 3 4 5 6 7 8 9 10 11 |
>>>1.pdf >>>10.pdf←注意 >>>11.pdf←注意 >>>2.pdf >>>3.pdf >>>4.pdf >>>5.pdf >>>6.pdf >>>7.pdf >>>8.pdf >>>9.pdf |
上記のファイル名のPDF(11コ)をsortedで並び替えすると、10.pdfと11.pdfが意図しない順番に並び替えられてしまいます。
したがって、数値で並び替えるときは、0埋めなどをしておくことが必要になります。
0埋めをして以下のようにファイル名を変更すると、sortedで並び替えても上記のような課題は発生しません。
ファイル番号を0埋めすると、意図した順番に並び替えられる。
プログラム
|
1 2 3 |
files=['01.pdf','02.pdf','03.pdf','04.pdf','05.pdf','06.pdf','07.pdf','08.pdf','09.pdf','10.pdf','11.pdf'] sfiles = sorted(files) [print(sfile) for sfile in sfiles] |
実行結果
|
1 2 3 4 5 6 7 8 9 10 11 |
>>>01.pdf >>>02.pdf >>>03.pdf >>>04.pdf >>>05.pdf >>>06.pdf >>>07.pdf >>>08.pdf >>>09.pdf >>>10.pdf >>>11.pdf |
このように、sortedでファイルを並び替えをするときには注意が必要です。
プログラム4|結合先のPDFを新規作成
|
1 2 |
# プログラム4|結合先のPDFを新規作成 doc = fitz.open() |
結合先となるPDFを新規で作成します。
プログラム5以降で結合するためのPDFの土台(足場)を作成するイメージです。
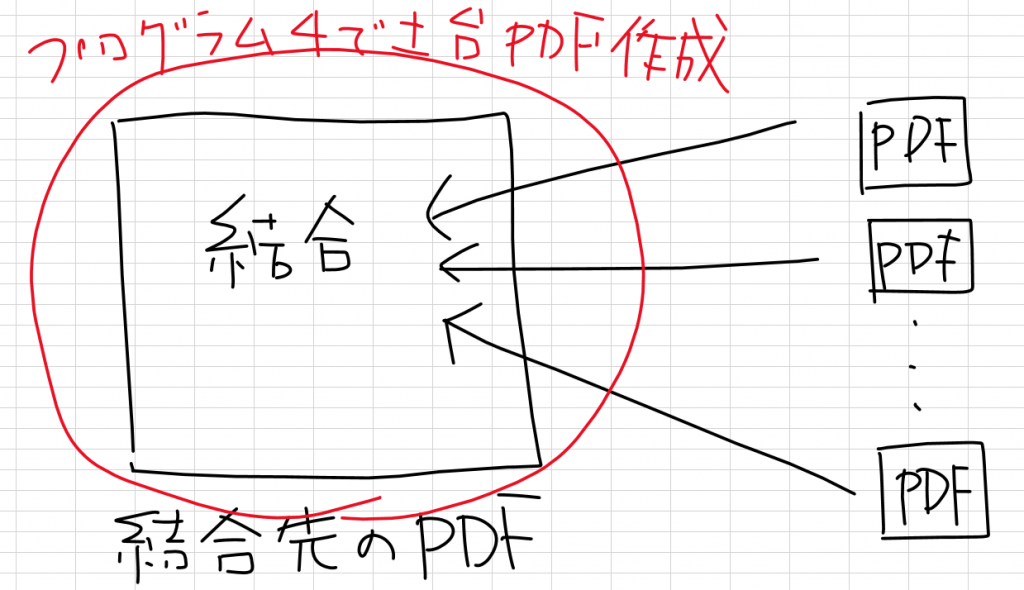
この土台に結合したいPDFを足していきます。(プログラム5以降)
プログラム5|結合元PDFを開く
|
1 2 3 |
# プログラム5|結合元PDFを開く for file in sfiles: infile = fitz.open(file) |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
for file in sfiles: |
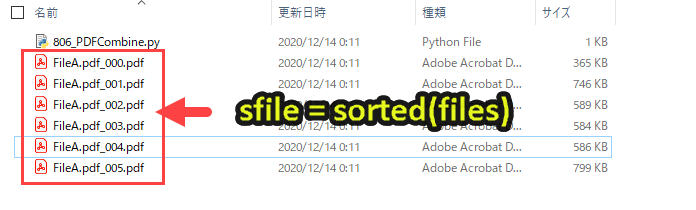
プログラム3で取得した結合したいPDF一覧を順番に処理をしていきます。(プログラム3で順番に並び替えたのは、ここで順番通りに結合していくため)
|
1 |
[print(file) for file in sfiles] |
実行結果
|
1 2 3 4 5 6 |
>>>D:\DropBox\Dropbox\Python\Program\800_PDF\806_PDF_Combine\FileA.pdf_000.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\806_PDF_Combine\FileA.pdf_001.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\806_PDF_Combine\FileA.pdf_002.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\806_PDF_Combine\FileA.pdf_003.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\806_PDF_Combine\FileA.pdf_004.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\806_PDF_Combine\FileA.pdf_005.pdf |
|
3 |
infile = fitz.open(file) |
変数infileという名前でsfile(結合したいPDF)を開きます。
ここで開いたPDFをプログラム6で結合します。
プログラム6|結合先PDFと結合元PDFのページ番号を指定
|
1 2 3 4 |
# プログラム6|結合先PDFと結合元PDFのページ番号を指定 doc_lastPage = len(doc) infile_lastPage = len(infile) doc.insertPDF(infile, from_page=0, to_page=infile_lastPage, start_at=doc_lastPage, rotate=0) |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
doc_lastPage = len(doc) |
結合先PDFの最終ページ数を取得します。
たとえば結合先PDF(土台となるPDF)のページ数が6のとき、「doc_lastPage = 6」となります。
最終ページ数は、結合先PDFにPDFを足していくときに使います。(start_at=doc_lastPage)
|
3 |
infile_lastPage = len(infile) |
結合元(結合したい)PDFの最終ページ数を取得します。
結合元のPDFは0~最終ページまで結合していきます。
そのため「最終ページ数」を取得しておかないと、最終ページまで結合がされません。
|
4 |
doc.insertPDF(infile, from_page=0, to_page=infile_lastPage, start_at=doc_lastPage, rotate=0) |
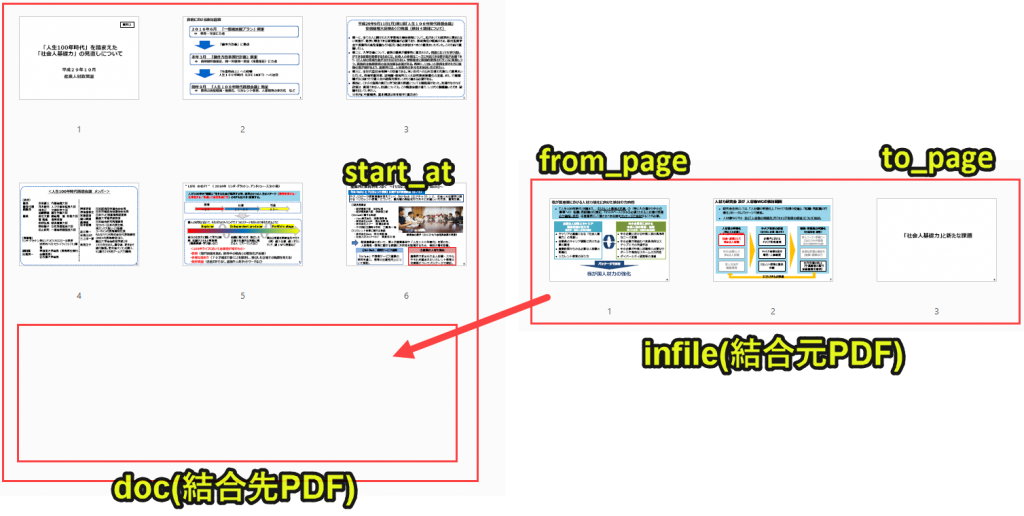
docとなる土台となるPDFに、infileのPDFを結合します。
設定は以下のとおりです。
・to_page = file_lastPage|infile(結合元PDF)の最終ページまで結合
・start_at=doc_lastPage|doc(土台PDF)の結合開始ページ
・rotate=0|回転角度は0度(横にしたい場合は90とする)
結合させたいPDFに応じて、変更していきます。
プログラム7|結合元PDFを閉じる
|
1 2 |
# プログラム7|結合元PDFを閉じる infile.close() |
結合元(結合したい)PDFを閉じます。
for文の繰り返しでプログラム5へ戻り、次のファイルを処理します。
プログラム8|結合先PDFを保存する
|
1 2 3 |
# プログラム8|結合先PDFを保存する filename = 'PDFs_joined_.pdf' doc.save(filename) |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
filename = 'PDFs_joined_.pdf' |
変数filenameを「PDFs_joined_.pdf」に設定します。
|
3 |
doc.save(filename) |
結合したPDFの名前をfilename(「PDFs_joined_.pdf」)として保存します。
プログラムの解説はここまでです。
Pythonについて詳しく理解したいなら
Pythonを活用すると、仕事を効率化できる幅を広げることができます。
たとえば私が実際にPythonを活用して効率化してきた作業は以下の記事で紹介しています。
興味がある人は以下の記事もご覧ください。
Python×効率化のサンプル
Pythonで効率化できる事例をサンプルコード付きで紹介しています。

Python×Excel
PythonとExcelで自動化できることを紹介しています。
事例も数多く紹介しているので、ぜひ参考にしてみてください。

Pythonって難しい?
Pythonの難易度などについては、以下で紹介しています。
勉強の参考になれば幸いです。
