

Pythonを使うとき、Pandasを使うとCSVの分析がカンタンになります。しかし、Python初心者だとPandasの実務でどのように活用するか分からない人も多いはずです。
そこで、私が実際の業務でどのようにPythonとPandasを活用しているかをお伝えします。
・毎月の売上データ(CSVファイル)の算出
→算出結果をチャットへ出力)
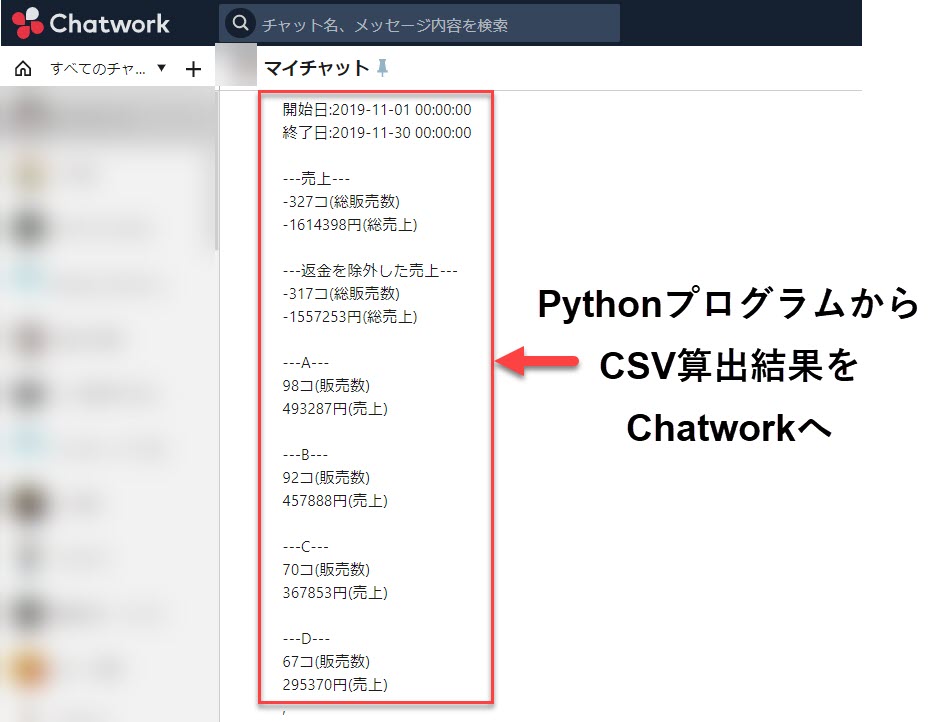
上記のように、私はPandasを使って毎月の売上データをChatに自動出力させています。
この記事では、上記のようなchatへの自動出力するPythonプログラムも含めて、実現方法を紹介していきます。
目次
- 1 Pythonで作る! 売上データの自動報告ツールの全体概要
- 2 ステップ1|自社ウェブサイトからCSVファイルをダウンロードしてフォルダに保管
- 3 ステップ2|CSVファイルを解析して1ヶ月分の売上データを解析してChatツールへ出力
- 3.1 プログラム1|ライブラリの設定
- 3.2 プログラム2|mainプログラム
- 3.3 プログラム2-1|CSVファイルが保存されているファイルパス取得
- 3.4 プログラム2-2|算出範囲である1ヵ月間の日付を取得
- 3.5 プログラム2-3|リストを設定
- 3.6 プログラム2-4|解析の範囲(開始日と終了日)をresultに格納
- 3.7 プログラム2-5|フォルダ内のCSVファイルを取得
- 3.8 プログラム2-6|取得したCSVファイルをPandasで解析
- 3.9 プログラム2-7|2条件で抽出する
- 3.10 プログラム2-8|resultに結果を格納する
- 3.11 プログラム2-9|3つの条件で抽出する
- 3.12 プログラム2-10|resultに結果を格納する
- 3.13 プログラム2-11|担当者別のデータを取得する
- 3.14 プログラム2-12|resultのデータを改行を入れる
- 3.15 プログラム2-13|プログラム3を起動する
- 3.16 プログラム2-14|CSVファイルを削除する
- 3.17 プログラム2-15|プログラム終了のメッセージ
- 3.18 プログラム3|Chatwork(チャットツール)へ出力するプログラム
- 3.19 プログラム3-1|チャットに出力するメッセージを作成する
- 3.20 プログラム3-2|Chatworkに通知する
- 3.21 プログラム4|プログラムを動かすときのおまじない
- 4 ステップ3|ステップ1~ステップ2が月初に起動するようにタスクスケジューラを設定
- 5 Python学習に興味がある人へ
Pythonで作る! 売上データの自動報告ツールの全体概要
まず、この記事で紹介する「売上データの自動報告ツール」について全体概要をお伝えします。
ステップ1|自社ウェブサイトからCSVファイルをダウンロードしてフォルダに保管
ステップ2|CSVファイルを解析して1ヶ月分の売上データを解析してChatツールへ出力
ステップ3|ステップ1~ステップ2が月初に起動するように設定
月初に売上データの算出結果がChatに出力される
月初になると、タスクスケジューラからPythonプログラムが起動し、以下のとおりチャットに1ヶ月分の売上データが出力されます。
たとえば、月初である2019/12/1には「2019/11/1~2019/11/30までの売上データを算出してChatに出力」してくれます。
ステップ1とステップ3は別の記事で紹介します
本記事では、ステップ1とステップ3については解説していません。その2つについては別記事で解説をします。
具体的には以下の表をご覧ください。
| ステップ | 内容 | 実現方法 |
|---|---|---|
| 1 | 自社ウェブサイトからCSVファイルをダウンロードしてフォルダに保管 | 別記事でプログラムを紹介 |
| 2 | CSVファイルを解析して1ヶ月分の売上データを解析してChatツールへ出力 | 本記事でプログラムを紹介 |
| 3 | ステップ1~ステップ3が月初に起動するように設定 | タスクスケジューラ(別記事で紹介) |
ステップ1|自社ウェブサイトからCSVファイルをダウンロードしてフォルダに保管
上述のとおり、ステップ1は別記事でお伝えします。
補足ですが、このステップ1はウェブサイトにアクセスしてCSVをダウンロードし、所定フォルダへ保管するプロセスです。
この「所定フォルダ」の保管場所はステップ2とリンクさせることで、ダウンロードしたCSVファイルを手動で移動させることなく、自動で処理を進めることができます。
なお、ステップ1を終えた時点でCSVファイルは以下のように所定フォルダに保管されるようにしています。
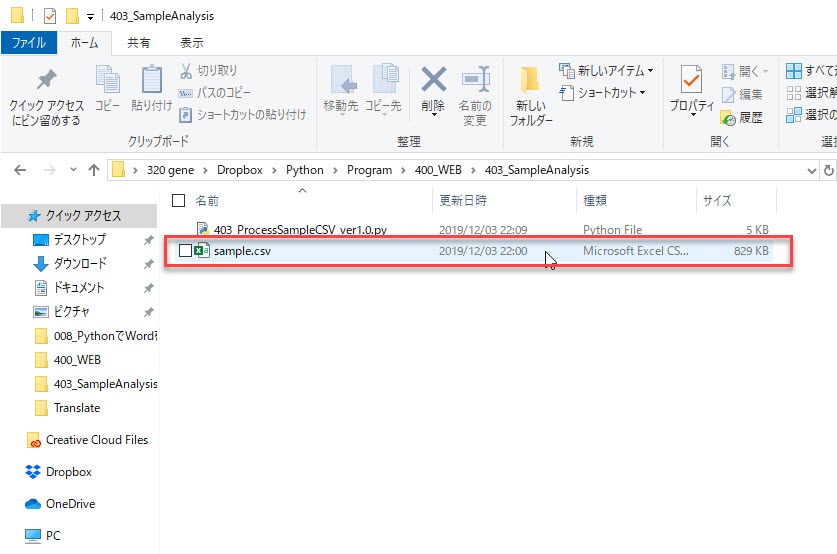
ステップ2では、上記の場所にCSVファイルが保管されていることを想定して、話を進めていきます。
なお、保管されているCSVファイルは以下のように10000行のデータが含まれています。当然ですが、以下はサンプルデータのため、実際の業務ではデータ数はもっと多いです。
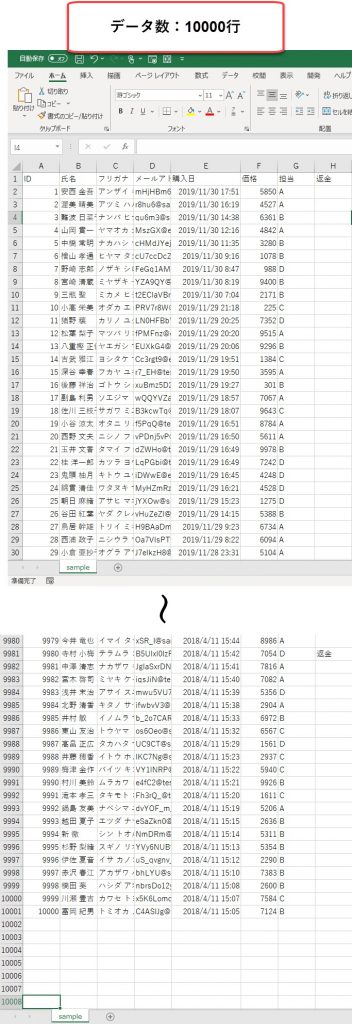
また、CSVファイルのヘッダー情報は以下です。
このヘッダー情報はPandasの算出で使用することになるので、覚えておく必要があります。
それでは以下でCSVファイルをPandasを使って解析していきます。
ステップ2|CSVファイルを解析して1ヶ月分の売上データを解析してChatツールへ出力
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 |
#プログラム1|ライブラリの設定 import pandas as pd from datetime import datetime, timedelta from dateutil.relativedelta import relativedelta import glob import os import requests #プログラム2|mainプログラム def main(): # プログラム2-1|CSVファイルが保存されているファイルパス取得 path = os.getcwd() csvpath=path +"\\*.csv" files=glob.glob(csvpath) # プログラム2-2|算出範囲である1ヵ月間の日付を取得 today = datetime.today() zerotoday = today.replace(hour=0,minute=0,second=0,microsecond=0) OneMonthBefore = zerotoday - relativedelta(months=1) Firstdate = OneMonthBefore.replace(day=1) Lastdate = (OneMonthBefore + relativedelta(months=1)).replace(day=1) - timedelta(days=1) Startdate= Firstdate Enddate = Lastdate # プログラム2-3|リストを設定 result=[] Tanto=["A","B","C","D"] # プログラム2-4|解析の範囲(開始日と終了日)をresultに格納 result.append("開始日:" + str(Startdate.strftime('%Y-%m-%d %H:%M:%S'))) result.append("終了日:" + str(Enddate.strftime('%Y-%m-%d %H:%M:%S'))) # プログラム2-5|フォルダ内のCSVファイルを取得 for file in files: filename = os.path.basename(file) if 'sample' in filename: # プログラム2-6|取得したCSVファイルをPandasで解析 sampledata = pd.read_csv(file, encoding='utf-8') # sampledata = pd.read_csv(file,encoding='cp932') utf-8でプログラムエラーが出る場合、cp932で開くとエラーを回避できる場合がある sampledata["購入日"] = pd.to_datetime(sampledata["購入日"]) # プログラム2-7|2条件で抽出する Total = sampledata[(sampledata['購入日'] >= Startdate) & (sampledata['購入日'] <= Enddate)] # プログラム2-8|resultに結果を格納する result.append("\n---売上---") result.append("-" + str(len(Total)) + "コ(総販売数)") result.append("-" + str(Total['価格'].sum()) + "円(総売上)") # プログラム2-9|3つの条件で抽出する Uriage = sampledata[(sampledata['購入日'] >= Startdate) & (sampledata['購入日'] <= Enddate) & ~ (sampledata['返金'] == "返金")] # プログラム2-10|resultに結果を格納する result.append("\n---返金を除外した売上---") result.append("-" + str(len(Uriage)) + "コ(総販売数)") result.append("-" + str(Uriage['価格'].sum()) + "円(総売上)") # プログラム2-11|担当者別のデータを取得する for x in Tanto: Syoukai = sampledata[(sampledata['購入日'] >= Startdate) & (sampledata['購入日'] <= Enddate) & (sampledata['担当']==x)] result.append("\n---" + str(x) + "---") result.append(str(len(Syoukai)) + "コ(販売数)") result.append(str(Syoukai['価格'].sum()) + "円(売上)") # プログラム2-12|resultのデータを改行を入れる message = "\n".join(result) # プログラム2-13|プログラム3を起動する SendChatwork(message) # プログラム2-14|CSVファイルを削除する os.remove(file) # プログラム2-15|プログラム終了のメッセージ print("Processed") #プログラム3|Chatwork(チャットツール)へ出力するプログラム def SendChatwork(message): # プログラム3-1|チャットに出力するメッセージを作成する sendmessage = "先月の結果\n" + message # プログラム3-2|Chatworkに通知する r_id='Chatworkで通知したい部屋番号を入れる' base_url='https://api.chatwork.com/v2' post_message_url='{}/rooms/{}/messages'.format(base_url, r_id) apikey='あなたのAPIkeyを入力する(事前にchatworkから取得する必要あり)' headers={'X-ChatworkToken': apikey} params={'body': sendmessage} r = requests.post(post_message_url, headers=headers, params=params) #プログラム4|プログラムを動かすときのおまじない if __name__ == "__main__": main() |
以上が本記事で紹介するプログラムです。
それでは、以下で上記のプログラムを解説していきます。
プログラム1|ライブラリの設定
|
1 2 3 4 5 6 7 |
#プログラム1|ライブラリの設定 import pandas as pd from datetime import datetime, timedelta from dateutil.relativedelta import relativedelta import glob import os import requests |
このプログラムでは、上記のライブラリを使用します。したがって、上記のライブラリはインストールしておきます。
用途は以下のとおりです。
from datetime import datetime, timedelta :日付取得で使用
from dateutil.relativedelta import relativedelta :1つ前の月始めと月終わりの日付を取得するときに使用
import glob:フォルダ内のCSVファイルを検索するときに使用
import os : ファイル削除に使用
import requests :Chatwork(チャットツール)に出力するときに使用
プログラム2|mainプログラム
|
1 2 |
#プログラム2|mainプログラム def main(): |
このプログラムのメインプロシージャを指し、ここがプログラム開始点ということを示します。
プログラム2-1|CSVファイルが保存されているファイルパス取得
|
1 2 3 4 |
# プログラム2-1|CSVファイルが保存されているファイルパス取得 path = os.getcwd() csvpath=path +"\\*.csv" files=glob.glob(csvpath) |
→Pythonプログラムが保管されているフォルダを変数「path」に取得する
ちなみに私のPCでは、以下のフォルダにpythonプログラムを保管しています。
したがって、「os.getcwd()」では上記のフォルダパスを取得します。
→変数「csvpath」に「.csvの拡張子をもつファイルパス」を取得する
→変数「files」に「.csvの拡張子をもつファイルパス」をすべて取得する
本記事では紹介していませんが、このプログラムは複数のCSVファイルがあることを想定しています。
したがって、上記のようなプログラムを入れることで、複数のCSVファイルを処理できるようにしています。
プログラム2-2|算出範囲である1ヵ月間の日付を取得
|
1 2 3 4 5 6 7 8 |
# プログラム2-2|算出範囲である1ヵ月間の日付を取得 today = datetime.today() zerotoday = today.replace(hour=0,minute=0,second=0,microsecond=0) OneMonthBefore = zerotoday - relativedelta(months=1) Firstdate = OneMonthBefore.replace(day=1) Lastdate = (OneMonthBefore + relativedelta(months=1)).replace(day=1) - timedelta(days=1) Startdate= Firstdate Enddate = Lastdate |
変数「today」に今の日付を取得
変数「zerotoday」にtodayで取得した今の日付の「時間、分、秒、マイクロ秒」をそれぞれ「0」に変更する
変数「OneMonthBefore」にzerotodayの日付を1ヶ月前に変更する
変数「Firstdate」を先月の月初の日付にする
変数「Lastdate」を先月の月末の日付にする
変数「Startdate」を先月の月末の日付にする
変数「Enddate」を先月の月末の日付にする
プログラム2-3|リストを設定
|
1 2 3 |
# プログラム2-3|リストを設定 result=[] Tanto=["A","B","C","D"] |
変数「result」をList型で定義する
変数「Tanto」をList型で定義して「A」「B」「C」「D」の4つの文字列を格納する
プログラム2-4|解析の範囲(開始日と終了日)をresultに格納
|
1 2 3 |
# プログラム2-4|解析の範囲(開始日と終了日)をresultに格納 result.append("開始日:" + str(Startdate.strftime('%Y-%m-%d %H:%M:%S'))) result.append("終了日:" + str(Enddate.strftime('%Y-%m-%d %H:%M:%S'))) |
プログラム2-5|フォルダ内のCSVファイルを取得
|
1 2 3 4 |
# プログラム2-5|フォルダ内のCSVファイルを取得 for file in files: filename = os.path.basename(file) if 'sample' in filename: |
フォルダ内のCSVファイルを全て取得して一つずつ調べる
CSVファイルの名前を取得する
IF文:CSVファイルの名前に「sample」という文字列が含まれていたら
プログラム2-6|取得したCSVファイルをPandasで解析
|
1 2 3 4 5 |
# プログラム2-6|取得したCSVファイルをPandasで解析 sampledata = pd.read_csv(file, encoding='utf-8') # sampledata = pd.read_csv(file,encoding='cp932') utf-8でプログラムエラーが出る場合、cp932で開くとエラーを回避できる場合がある sampledata["購入日"] = pd.to_datetime(sampledata["購入日"]) |
取得したCSVファイルを読み込む、CSVデータをsampledataに格納します。
# sampledata = pd.read_csv(file,encoding=’cp932′)
utf-8でプログラムエラーが出る場合、cp932で開くとエラーを回避できる場合がある
取得したCSVファイルの「購入日」の列の情報をdatetimeに変換する(変換することで、日付の比較ができるようになる)
プログラム2-7|2条件で抽出する
|
1 2 |
# プログラム2-7|2条件で抽出する:CSVファイルの購入日の列のデータの内、月始め~月終わりの期間に入っているデータのみ抽出する Total = sampledata[(sampledata['購入日'] >= Startdate) & (sampledata['購入日'] <= Enddate)] |
CSVファイルの購入日の列のデータの内、月始め~月終わりの期間に入っているデータのみ抽出していきます。
2条件を抽出するときは、以下のように記載します。
Total = sampledata[(条件1) & (条件2)] と書きます。
条件は()で閉じます。2つの条件を「&」でつなぐと、「かつ(2条件を両方みたす場合)」となります。
ちなみに「&」を「|」に変更することで、「または(2条件のどちらかを満たす場合)」にできます。
条件1「sampledata[‘購入日’] >= Startdate」とすることで、「購入日がStartdate(月初の日付)より後の日付」を指します。
条件2「sampledata[‘購入日’] <= Enddate)」とすることで、「購入日がEnddate(月末の日付)より前の日付」を指します。 こうすることで、月初から月末までを抽出することができます。 繰り返しになりますが、Total = sampledata[(条件1) & (条件2)] と書きます。[]と()の使い分けに注意してください。
プログラム2-8|resultに結果を格納する
|
1 2 3 4 |
# プログラム2-8|resultに結果を格納する result.append("\n---売上---") result.append("-" + str(len(Total)) + "コ(総販売数)") result.append("-" + str(Total['価格'].sum()) + "円(総売上)") |
「str(len(Total))」 はTotalとして抽出されたデータ数を指す。したがって販売総数を意味します
「str(Total[‘価格’].sum())」はTotalとして抽出されたデータ数の内、ヘッダー情報が「価格」の列の数値を合計値となります。したがって売上額を意味します
これらをresultに格納します。resultは最終的にchatツールに出力するメッセージです。
したがって、chatに出力するメッセージも合わせてresultに格納していきます。
プログラム2-9|3つの条件で抽出する
|
1 2 |
# プログラム2-9|3つの条件で抽出する Uriage = sampledata[(sampledata['購入日'] >= Startdate) & (sampledata['購入日'] <= Enddate) & ~ (sampledata['返金'] == "返金")] |
ここでは3つの条件で抽出しています。
Uriage = sampledata[(条件1) & (条件2) & ~ (条件3)]
「~ (条件3)」と書くことで、条件3に該当しないデータを指します。
つまり「条件1」かつ「条件2」かつ「条件3ではない」データを取得することが可能です。
条件1「sampledata[‘購入日’] >= Startdate」とすることで、「購入日がStartdate(月初の日付)より後の日付」を指します。
条件2「sampledata[‘購入日’] <= Enddate)」とすることで、「購入日がEnddate(月末の日付)より前の日付」を指します。 条件3「sampledata['返金'] == "返金"」とすることで、「CSVの"返金"の列に"返金"という文字列が入っていないデータ」を指します。
プログラム2-10|resultに結果を格納する
|
1 2 3 4 |
# プログラム2-10|resultに結果を格納する result.append("\n---返金を除外した売上---") result.append("-" + str(len(Uriage)) + "コ(総販売数)") result.append("-" + str(Uriage['価格'].sum()) + "円(総売上)") |
「プログラム2-8」と同じことを行っています。
プログラム2-11|担当者別のデータを取得する
|
1 2 3 4 5 6 |
# プログラム2-11|担当者別のデータを取得する for x in Tanto: Syoukai = sampledata[(sampledata['購入日'] >= Startdate) & (sampledata['購入日'] <= Enddate) & (sampledata['担当']==x)] result.append("\n---" + str(x) + "---") result.append(str(len(Syoukai)) + "コ(販売数)") result.append(str(Syoukai['価格'].sum()) + "円(売上)") |
「プログラム2-3」でTantoという変数に「A」「B」「C」「D」の4つを格納しておきました。
実際のデータは以下のように「担当」の列に「A」「B」「C」「D」が記載されています。
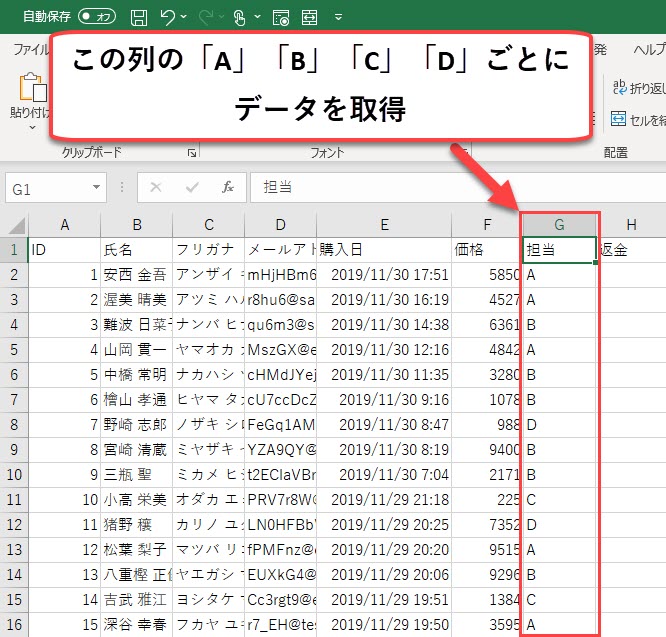
そこで、TantoをFor文で繰り返し処理することで、「A」「B」「C」「D」の4名の売上データを取得します。
「(sampledata[‘担当’]==x)」の部分で、xに「A」「B」「C」「D」の4つを入れることで、それぞれの担当者ごとにデータをソートできます。
result.append(str(Syoukai[‘価格’].sum()) + “円(売上)”)
上記のプログラムで、「A」「B」「C」「D」の4名の販売数と売上額を取得して、resultに格納します。
プログラム2-12|resultのデータを改行を入れる
|
1 2 |
# プログラム2-12|resultのデータを改行を入れる message = "\n".join(result) |
変数result(ここまで販売数や売上額を入れ込んでいる)を要素ごとに「\n(改行)」を挿し込む
プログラム2-13|プログラム3を起動する
|
1 2 |
# プログラム2-13|プログラム3を起動する SendChatwork(message) |
後述しているプログラム3を呼び出します。そのとき、変数message(プログラム2-12で作成済)を引数として渡します
プログラム2-14|CSVファイルを削除する
|
1 2 |
# プログラム2-14|CSVファイルを削除する os.remove(file) |
解析したCSVファイルを削除します。
削除する理由は、次の月に解析するときに邪魔になるからです。
ダウンロードしたCSVファイルを残しておくと、次の月に古いCSVファイルを解析対象にしてしまうリスクがあるのです。
そのため、処理が終わった段階で削除します。
プログラム2-15|プログラム終了のメッセージ
|
1 2 |
# プログラム2-15|プログラム終了のメッセージ print("Processed") |
プログラム実行が完了したことを知らせるメッセージを出力します。
プログラム3|Chatwork(チャットツール)へ出力するプログラム
|
1 2 |
#プログラム3|Chatwork(チャットツール)へ出力するプログラム def SendChatwork(message): |
プログラム2-13で呼び出されるプログラムです。
プログラム3-1とプログラム3-2の処理が終わってからプログラム2-14に戻ります。
プログラム3-1|チャットに出力するメッセージを作成する
|
1 2 |
# プログラム3-1|チャットに出力するメッセージを作成する sendmessage = "先月の結果\n" + message |
チャットに出力するメッセージを作成します。
プログラム2-12で作成したmessageの先頭に「先月の結果\n」を差し込みます。
なお「\n」は改行を指します。chatでは「\n」は改行に変換されます。
プログラム3-2|Chatworkに通知する
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# プログラム3-2|Chatworkに通知する r_id='Chatworkで通知したい部屋番号を入れる' base_url='https://api.chatwork.com/v2' post_message_url='{}/rooms/{}/messages'.format(base_url, r_id) apikey='あなたのAPIkeyを入力する(事前にchatworkから取得する必要あり)' headers={'X-ChatworkToken': apikey} params={'body': sendmessage} r = requests.post(post_message_url, headers=headers, params=params) |
上記はPythonでchatworkに通知するときのプログラムです。
以下の2つは、使用者が自分で入力する必要があります。
・apikey=’あなたのAPIkeyを入力する(事前にchatworkから取得する必要あり)’
プログラム4|プログラムを動かすときのおまじない
|
1 2 3 |
#プログラム4|プログラムを動かすときのおまじない if __name__ == "__main__": main() |
このプログラムはおまじないとして、このように書くと覚えてそのまま使うようにしておくと良いです。
詳しい説明は他のサイトに譲ります。
ステップ3|ステップ1~ステップ2が月初に起動するようにタスクスケジューラを設定
ここで紹介したプログラムは毎月1日起動するように設定しています。
なぜなら一つ前の月の売上データをチャットに通知するからです。
そのため、windowsPCを使っている私はタスクスケジューラに毎月1日に、このプログラムを起動するようにセットしています。
タスクスケジューラにセットして、毎月プログラムを動かす方法は別記事で紹介します。
Python学習に興味がある人へ
ここまでPythonプログラムについて紹介してきました。
Pythonの処理を上手く組み合わせることで、定期的に実行する処理を自動化することができます。
こうすることで月初の作業を忘れずに、かつ正確に実行できます。
ここでは、売上データの定期実行を紹介しましたが、Pythonを使えば他にも様々な作業を効率化できます。
それらについては別の記事で紹介をしているので、興味がある人はそちらをご覧ください。