
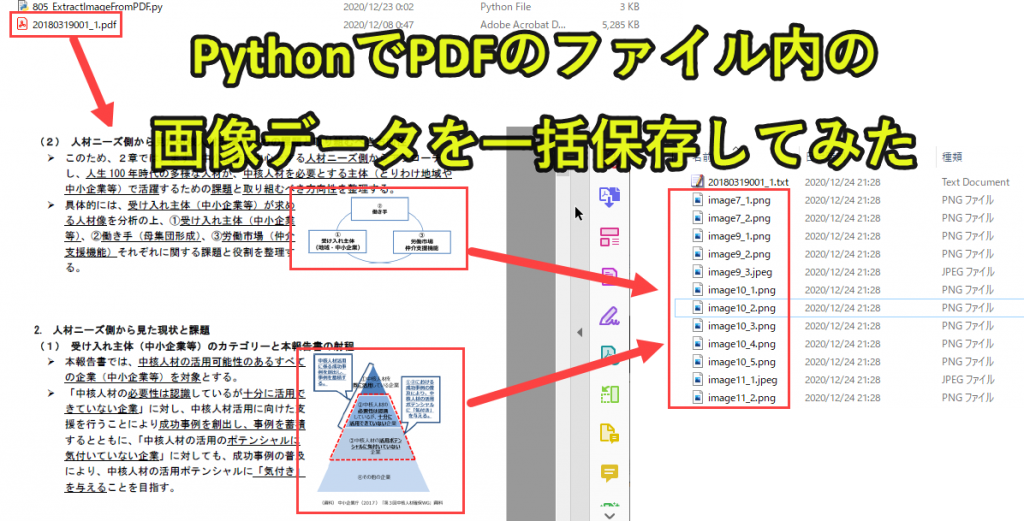
Pythonを使うとPDFの画像を全て取得することができます。
ここでは実務の事例として、PDFの画像を全て取得しフォルダ内の保存するPythonプログラムを紹介します。
・フォルダ内に保存する
それでは以下で詳しく紹介していきます。
目次
- 1 PythonでPDF内の画像を取得しフォルダへ保存
- 2 Pythonプログラムを実行するための準備|PDFの事前保管とライブラリ
- 3 Pythonプログラム解説
- 3.1 プログラム1|ライブラリの設定
- 3.2 プログラム2|「.py」が保管されているフォルダを取得
- 3.3 プログラム3|取得した画像を保管するためのフォルダ作成
- 3.4 プログラム4|読み込んだ画像情報を格納するリスト
- 3.5 プログラム5|PDF読み込み
- 3.6 プログラム6|PDFをページごとに読み込み
- 3.7 プログラム7|ページごとの画像を読み込む
- 3.8 プログラム8|ページごとの画像情報をリストに格納
- 3.9 プログラム9|ページ内の画像情報を順々に処理
- 3.10 プログラム10|画像を取得
- 3.11 プログラム11|PILライブラリで画像として取得
- 3.12 プログラム12|画像を保存する
- 3.13 プログラム13|PDFの画像取得情報をテキストファイルとして保存
- 4 本プログラムの注意点
- 5 Pythonについて詳しく理解したいなら
PythonでPDF内の画像を取得しフォルダへ保存
今回は以下の作業をpythonで行います。
1. PDFを読み込み(すべてのページ)
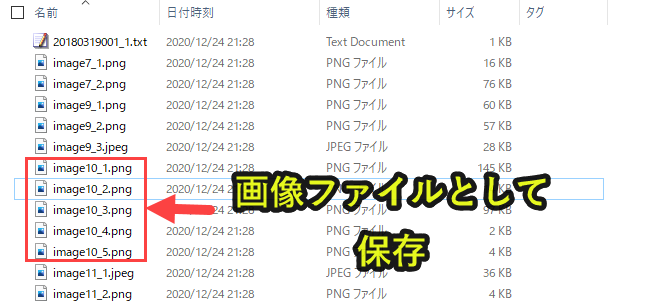
2. 画像を取得し所定フォルダ内に保存する
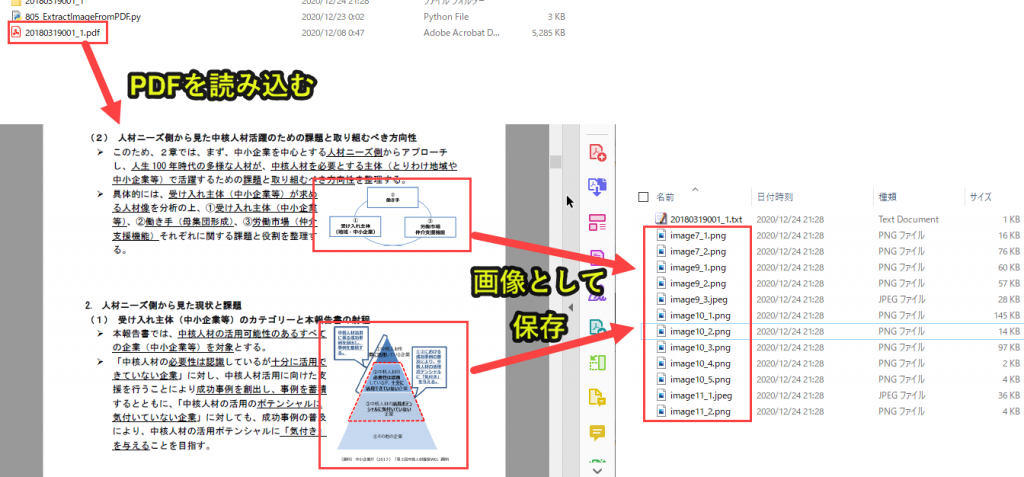
PDFの全ページを読み込んで画像を所定フォルダに保存していきます。
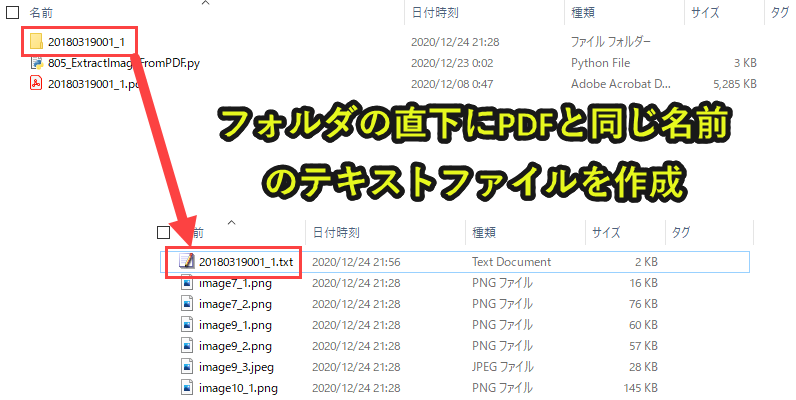
なお所定フォルダは自動作成し、読み込んだ画像情報を一覧できるテキストファイルも自動作成していきます。
Pythonプログラムを実行するための準備|PDFの事前保管とライブラリ
1. 画像を取得したいPDFをフォルダに保存(「.py」と同じフォルダ)
2. 必要なライブラリをインストール
準備1|画像を取得したいPDFをフォルダに保存(「.py」と同じフォルダ)
画像を取得したいPDFをフォルダに保存します。

Pythonファイル「.py」と同じフォルダにPDFを保存すること
後半で紹介するプログラムをそのまま使用する場合は、「.py」と「.pdf」が同じフォルダでないとエラーが発生します。
フォルダを指定したい場合は、本記事で紹介するプログラムを一部変更する必要がありますので、ご注意ください。
準備2|必要なライブラリをインストール
今回は以下の2つのライブラリをインストールします。
pip install pymupdf
PDFから画像データを取得するときに使用するライブラリです。
pip install Pillow
PIL(Python Imaging Library)とは、Pythonで画像を処理するためのライブラリです。
pymupdfで取得した画像データを画像として取得するときに使用します。
上記をインストールしておかないと動かないので、注意が必要です。
Pythonプログラム解説
この記事で紹介するプログラムを解説しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
# プログラム1|ライブラリ設定 import fitz import os from PIL import Image import io # プログラム2|「.py」が保管されているフォルダを取得 curdir = os.getcwd() # プログラム3|取得した画像を保管するためのフォルダ作成 file = '20180319001_1.pdf' filename = file.replace('.pdf','') path = os.path.join(curdir, filename) if not os.path.isdir(path): os.makedirs(path) # プログラム4|読み込んだ画像情報を格納するリスト info = [] # プログラム5|PDF読み込み pdf_file = fitz.open(file) # プログラム6|PDFをページごとに読み込み for pageNo in range(len(pdf_file)): page = pdf_file[pageNo] # プログラム7|ページごとの画像を読み込む image_list = page.getImageList() # プログラム8|ページごとの画像情報をリストに格納 if len(image_list) > 0: info.append(f'{pageNo}ページには{len(image_list)}コの画像ファイル') else: info.append(f'{pageNo}ページには0コの画像ファイル') # プログラム9|ページ内の画像情報を順々に処理 for index, img in enumerate(image_list, start=1): # プログラム10|画像を取得 xref = img[0] base_image = pdf_file.extractImage(xref) image_ext = base_image['ext'] image_bytes = base_image['image'] # プログラム11|PILライブラリで画像として取得 image = Image.open(io.BytesIO(image_bytes)) # プログラム12|画像を保存する imagefilepath = os.path.join(path, f'image{pageNo+1}_{index}.{image_ext}') image.save(open(imagefilepath, 'wb')) # プログラム13|PDFの画像取得情報をテキストファイルとして保存 newfilename = os.path.join(path, f'{filename}.txt') res = '\n'.join(info) with open(newfilename, 'w') as f: f.write(res) |
以下で詳しく説明しています。
プログラム1|ライブラリの設定
|
1 2 3 4 5 |
# プログラム1|ライブラリ設定 import fitz import os from PIL import Image import io |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
import fitz |
fitzはpymupdfのライブラリを操作するときに使用します。
|
3 |
import os |
osはフォルダ指定で使います。
これでpythonファイルや対象PDFが保管されているフォルダパスを取得します。
|
4 |
from PIL import Image |
画像情報を取得するときに使います。
|
5 |
import io |
こちらも画像処理をする際に使用します。
プログラム2|「.py」が保管されているフォルダを取得
|
1 2 |
# プログラム2|「.py」が保管されているフォルダを取得 curdir = os.getcwd() |
現在のフォルダを取得します。
ここでは「.py」ファイルが保管されているフォルダを指定します。
|
1 2 |
curdir = os.getcwd() print(curdir) |

実行結果
|
1 |
>>>D:\DropBox\Dropbox\Python\Program\800_PDF\805_PDF_ExtractImges |
「os.getcwd()」で「.py」ファイルが保管されているフォルダを取得できます。
プログラム3|取得した画像を保管するためのフォルダ作成
|
1 2 3 4 5 6 |
# プログラム3|取得した画像を保管するためのフォルダ作成 file = '20180319001_1.pdf' filename = file.replace('.pdf','') path = os.path.join(curdir, filename) if not os.path.isdir(path): os.makedirs(path) |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
file = '20180319001_1.pdf' |

「20180319001_1.pdf」というファイル名のPDFを取得します。
今回の事例ではこのファイル名ですが、もしこのプログラムを使う場合は、ここにご自身が扱いたいPDFファイル名を入れる必要があります。
なお、このファイル名はフォルダ作成のときに使用します。
フォルダ名にするには「.pdf」が邪魔なので、次のプログラムで「.pdf」を除去します。
|
3 |
filename = file.replace('.pdf','') |
「file.replace(‘.pdf’,”)」とすることで、「file = ‘20180319001_1.pdf’」から「.pdf」を削除します。
したがって、filename = 「20180319001_1」となります。
これで「.pdf」を除去することで、フォルダ名として使用することができます。
しかし「20180319001_1」だけでは、フォルダを作成できないため、フルパスを取得します。
|
4 |
path = os.path.join(curdir, filename) |
「os.path.join()」を使って、curdir(現在のパス)とfilename(20180319001_1)を結合させて、フォルダパスを作成します。
|
1 2 3 4 |
file = '20180319001_1.pdf' filename = file.replace('.pdf','') path = os.path.join(curdir, filename) print(path) |
実行結果
|
1 |
>>>D:\DropBox\Dropbox\Python\Program\800_PDF\805_PDF_ExtractImges\20180319001_1 |
このフォルダパスを使ってフォルダを作成します。
しかし同じ名前のフォルダが存在する場合、エラーが出てしまいます。
そこで、if文を使って同じ名前のフォルダが存在するかどうかをチェックします。
|
5 |
if not os.path.isdir(path): |
このプログラムで、「もしpathで指定したのと同じフォルダが存在しなければ」というif文で検証します。
この事例では、「path = ‘D:\DropBox\Dropbox\Python\Program\800_PDF\805_PDF_ExtractImges\20180319001_1’」です。
要は「.py」ファイルと同じ階層に「20180319001_1」のフォルダが存在するかどうかをチェックします。
もし同じ名前のフォルダがなければ次のプログラムでフォルダを作成します。
|
6 |
os.makedirs(path) |
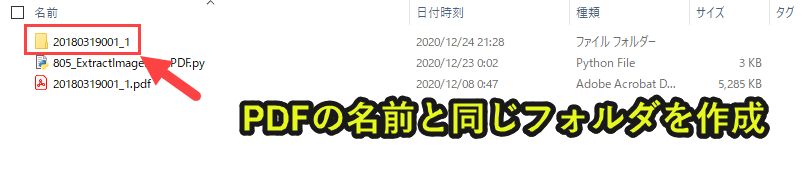
このようにPDFと同じ名前のフォルダを作成します。
プログラム4|読み込んだ画像情報を格納するリスト
|
1 2 |
# プログラム4|読み込んだ画像情報を格納するリスト info = [] |
infoというリストを作成します。
このinfoというリストにPDFから取得した画像情報を格納していきます。(プログラム8)
プログラム5|PDF読み込み
|
1 2 |
# プログラム5|PDF読み込み pdf_file = fitz.open(file) |
プログラム2で設定したfile(20180319001_1.pdf)を読み込みます。
プログラム6|PDFをページごとに読み込み
|
1 2 3 |
# プログラム6|PDFをページごとに読み込み for pageNo in range(len(pdf_file)): page = pdf_file[pageNo] |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
for pageNo in range(len(pdf_file)): |
for文を使い、pdfを1ページずつ読み込んでいきます。
今回扱うPDFは全部で64ページあります。
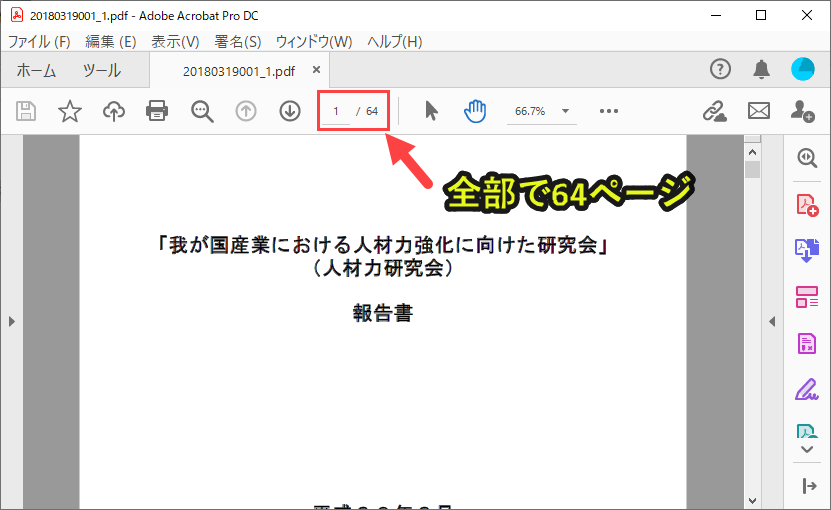
len(pdf_file)でpdfのページ数を取得します。
|
1 2 |
for pageNo in range(len(pdf_file)): print(pageNo) |
実行結果
|
1 2 3 4 5 6 |
>>>0 >>>1 >>>2 中略 >>>62 >>>63 |
0で開始して63で終了しているため、全部で64ページあることが分かります。
このようにfor文でpageNoに1ページずつ割り当てながら、1ページずつ処理していきます。
|
3 |
page = pdf_file[pageNo] |
pdf_file[ページ番号]で、各ページのPDFをpageとして読み込みます。
このpage内に含まれる画像データを以下のプログラムで処理していきます。
プログラム7|ページごとの画像を読み込む
|
1 2 |
# プログラム7|ページごとの画像を読み込む image_list = page.getImageList() |
「page.getImageList()」でページ内の画像データを取得することができます。
取得したリストはimage_listとして扱います。
プログラム8|ページごとの画像情報をリストに格納
|
1 2 3 4 5 |
# プログラム8|ページごとの画像情報をリストに格納 if len(image_list) > 0: info.append(f'{pageNo}ページには{len(image_list)}コの画像ファイル') else: info.append(f'{pageNo}ページには0コの画像ファイル') |
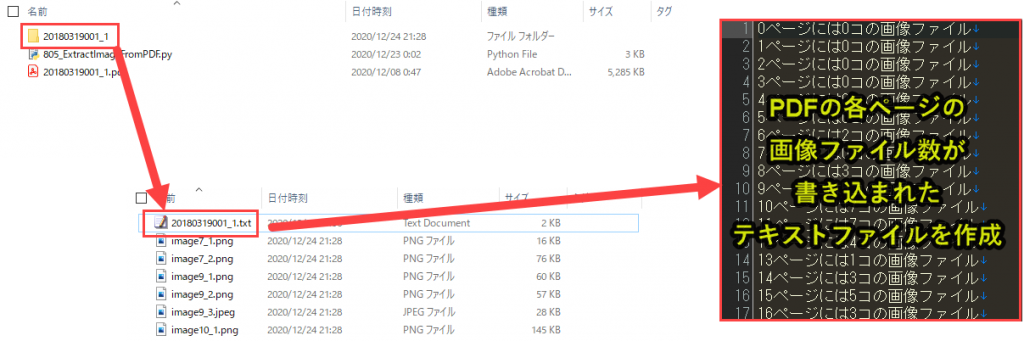
プログラム8で取得したinfoのデータは、プログラム13で使います。
具体的には、PDFに含まれる画像データをサマリーとしてテキストファイルに出力するのですが、そのときのデータとして使用します。
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
if len(image_list) > 0: |
「image_listに含まれる要素が0より大きければ」というif文を採用しています。
もしimage_listに画像要素が含まれていれば、以下のプログラムを実行します。
|
3 |
info.append(f'{pageNo}ページには{len(image_list)}コの画像ファイル') |
info(プログラム4)というリストに「f'{pageNo}ページには{len(image_list)}コの画像ファイル’」を追加していきます。
・len(image_list)はページ内の画像データ数
上記の2つをリストに追加していきます。
|
4 |
else: |
elseは、「image_listに含まれる要素が0」の場合を指します。
つまり、もしimage_listに画像要素が0であれば、以下のプログラムを実行します。
|
5 |
info.append(f'{pageNo}ページには0コの画像ファイル') |
info(プログラム4)というリストに「f'{pageNo}ページには0コの画像ファイル’」を追加していきます。
プログラム9|ページ内の画像情報を順々に処理
|
1 2 |
# プログラム9|ページ内の画像情報を順々に処理 for index, img in enumerate(image_list, start=1): |
enumerateでimage_listの要素数index, 要素内容imgをそれぞれ繰り返し処理をしていきます。
なおstart=1で、要素1から繰り返し処理を行うようにしています。
プログラム10|画像を取得
|
1 2 3 4 5 |
# プログラム10|画像を取得 xref = img[0] base_image = pdf_file.extractImage(xref) image_ext = base_image['ext'] image_bytes = base_image['image'] |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
xref = img[0] |
xrefで画像番号を取得することができます。
xrefは以下のような数字として保存されています。
|
1 2 3 |
for index, img in enumerate(image_list, start=1): xref = img[0] print(xref) |
実行結果
|
1 2 3 4 5 6 7 |
中略 >>>32 >>>33 >>>34 >>>35 >>>36 中略 |
このデータを用いて、pdfの画像データを取得します。
|
3 |
base_image = pdf_file.extractImage(xref) |
xrefで取得した画像番号を用いて、画像データを取得します。
|
1 2 3 4 |
for index, img in enumerate(image_list, start=1): xref = img[0] base_image = pdf_file.extractImage(xref) print(base_image) |
実行結果
|
1 2 3 4 5 6 7 |
中略 >>>\xec\xe1\xe3\xc7\x1b\xc2\(中略) >>>\xba\xde\xae\xae\xcf\x9f\(中略) >>>\xc3e8\x7fgg\xb7\x85\xb1\(中略) >>>\xec\xeaZ\xe7\xe1\x04\xc7c\(中略) >>>\xc5d\x00\x18\x81\xda\x01b\(中略) 中略 |
上記のような画像データを取得します。
|
4 |
image_ext = base_image['ext'] |
base_imageの中の[‘ext’]データを取得します。(base_imageの中からextをキーにして取得した値をimage_extとする)
image_extは画像の拡張子を取得します。
|
1 2 3 4 5 |
for index, img in enumerate(image_list, start=1): xref = img[0] base_image = pdf_file.extractImage(xref) image_ext = base_image['ext'] print(image_ext) |
実行結果
|
1 2 3 4 5 6 7 |
中略 >>>png(中略) >>>png(中略) >>>png(中略) >>>png(中略) >>>png(中略) 中略 |
上記のような画像の拡張子を取得します。
pngやjpegの拡張子を取得し、プログラム12で画像を保存するときに活用します。
|
5 |
image_bytes = base_image['image'] |
base_imageの中の[‘image’]データを取得します。(base_imageの中からimageをキーにして取得した値をimage_bytesとする)
image_bytesは画像情報をバイトとして取得します。
|
1 2 3 4 5 6 |
for index, img in enumerate(image_list, start=1): xref = img[0] base_image = pdf_file.extractImage(xref) image_ext = base_image['ext'] image_bytes = base_image['image'] print(image_bytes) |
実行結果
|
1 2 3 4 5 6 7 |
中略 >>>\xbb\xc1\xa3\x88\xee\xe5%\xa0\xdbL!(中略) >>>\xf3\xfbwo\xb5\xef\xd0E\xb3I\x13l(中略) >>>\xe1\xbf.\xe6B\xfe\xf0\xdc\xde\xba~(中略) >>>\x19r\xc0\xca\xf4y)\x91y)\tfY\x1d\xbbt(中略) >>>\x87\xc6\xc7n1\x0bnq\xde\xd1\x88\xd0\xc0(中略) 中略 |
上記のような画像の拡張子を取得します。
プログラム11|PILライブラリで画像として取得
|
1 2 |
# プログラム11|PILライブラリで画像として取得 image = Image.open(io.BytesIO(image_bytes)) |
バイトで取得した画像情報を画像変換します。
|
1 2 |
image = Image.open(io.BytesIO(image_bytes)) print(image) |
実行結果
|
1 2 3 4 5 6 7 |
中略 >>><PIL.PngImagePlugin.PngImageFile image mode=RGB size=921x237 at 0x19FAE6ED668> >>><PIL.PngImagePlugin.PngImageFile image mode=RGB size=298x137 at 0x19FAE6ED6D8> >>><PIL.PngImagePlugin.PngImageFile image mode=RGB size=921x236 at 0x19FAE6ED748> >>><PIL.PngImagePlugin.PngImageFile image mode=L size=1514x465 at 0x19FAE6ED780> >>><PIL.PngImagePlugin.PngImageFile image mode=RGB size=1514x465 at 0x19FAE6ED860> 中略 |
これで画像として取り扱うことができるようになります。
プログラム12|画像を保存する
|
1 2 3 |
# プログラム12|画像を保存する imagefilepath = os.path.join(path, f'image{pageNo+1}_{index}.{image_ext}') image.save(open(imagefilepath, 'wb')) |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
imagefilepath = os.path.join(path, f'image{pageNo+1}_{index}.{image_ext}') |
「f'{}_{}’」でフォーマットすることで、変数をテキストに変換し、imagefilepath(ファイルパス)とします。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
imagefilepath = os.path.join(path, f'image{pageNo+1}_{index}.{image_ext}') print(imagefilepath) 実行結果 <pre> 中略 >>>D:\DropBox\Dropbox\Python\Program\800_PDF\805_PDF_ExtractImges\20180319001_1\image10_1.png >>>D:\DropBox\Dropbox\Python\Program\800_PDF\805_PDF_ExtractImges\20180319001_1\image10_2.png >>>D:\DropBox\Dropbox\Python\Program\800_PDF\805_PDF_ExtractImges\20180319001_1\image10_3.png >>>D:\DropBox\Dropbox\Python\Program\800_PDF\805_PDF_ExtractImges\20180319001_1\image10_4.png >>>D:\DropBox\Dropbox\Python\Program\800_PDF\805_PDF_ExtractImges\20180319001_1\image10_5.png 中略 |
上記のようにファイルパスを作成します。
|
3 |
image.save(open(imagefilepath, 'wb')) |
作成したファイルパス(imagefilepath)を用いてファイルを保存します。
プログラム13|PDFの画像取得情報をテキストファイルとして保存
|
1 2 3 4 5 |
# プログラム13|PDFの画像取得情報をテキストファイルとして保存 newfilename = os.path.join(path, f'{filename}.txt') res = '\n'.join(info) with open(newfilename, 'w') as f: f.write(res) |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
newfilename = os.path.join(path, f'{filename}.txt') |
「path(プログラム3)」と「filename(プログラム3).txt」を結合させて、ファイルパスを取得します。
|
3 |
res = '\n'.join(info) |
info(プログラム8)で取得したリストの各要素を結合していきます。
「’\n’.join(info)」とすることで、各要素を結合するときに改行(\n)します。
|
4 |
with open(newfilename, 'w') as f: |
newfilenameで作成したテキストを書き込みモードで開きます。
このnewfilenameにres(infoの各要素を改行でつないだ情報)を以下のプログラムで書き込みます。
|
5 |
f.write(res) |
テキストに書き込みを行います。
プログラムの解説はここまでです。
本プログラムの注意点
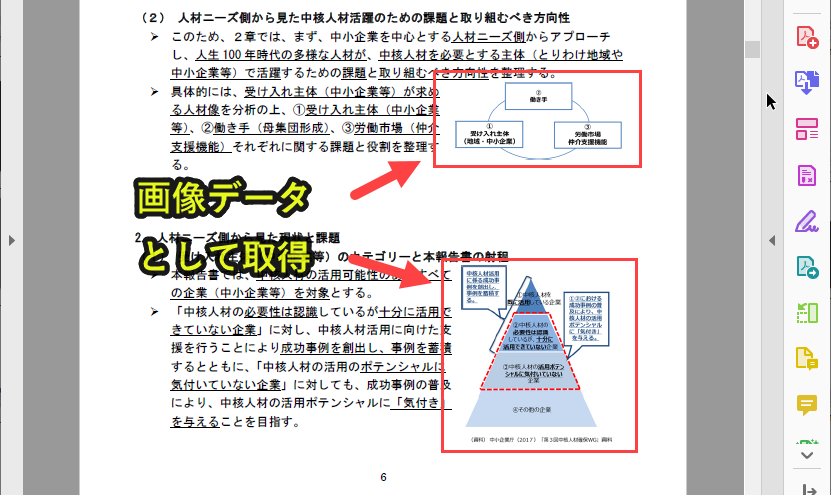
本プログラムはPDF内の画像を全て取得できますが、画像が切れる場合もあります。

たとえば上記のようなものが該当します。
一気に画像を取得するメリットはありますが、完全な状態で画像を取得できるわけではないことを理解した上で使用することをオススメします。
ただそれでも画像を全て取得する点においては威力を発揮するプログラムです。
使い所をハマれば、劇的な効率化を実現してくれるはずです。
Pythonについて詳しく理解したいなら
Pythonを活用すると、仕事を効率化できる幅を広げることができます。
たとえば私が実際にPythonを活用して効率化してきた作業は以下の記事で紹介しています。
興味がある人は以下の記事もご覧ください。
Python×効率化のサンプル
Pythonで効率化できる事例をサンプルコード付きで紹介しています。

Python×Excel
PythonとExcelで自動化できることを紹介しています。
事例も数多く紹介しているので、ぜひ参考にしてみてください。

Python×PDF
PythonとPDFで自動化できることを紹介しています。

Pythonって難しい?
Pythonの難易度などについては、以下で紹介しています。
勉強の参考になれば幸いです。
