
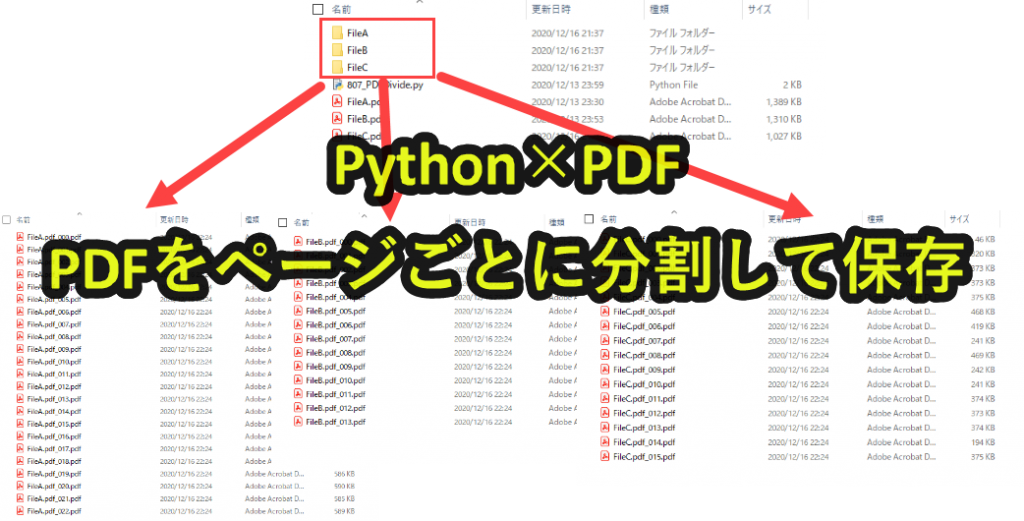
Pythonを使うとPDFをまとめて分割することができます。
ここでは実務の事例として、複数のPDFをページごとに分割しフォルダに保管するPythonプログラムを紹介します。
この記事では以下についてお伝えしていきます。
・分割したPDFは新しく作成したフォルダへ保管
それでは以下で詳しく紹介していきます。
目次
Pythonで複数PDFを読み込み、ページごとに分割する
今回は以下の作業をpythonで行います。
1. フォルダ内のPDFを全て読み込む
2. それぞれのPDFをページごとに分割して保存

上記のように、フォルダ内のPDFを分割して、ページごとに新しいPDFに作成します。
なお分割したPDFは新しいフォルダに自動で保管されるようにプログラムを組んでいきます。
Pythonプログラムを実行するための準備|PDFの事前保管とライブラリ
1. 分割したいPDFをフォルダに保存(「.py」と同じフォルダ)
2. 必要なライブラリをインストール
準備1|分割したいPDFをフォルダに保存(「.py」と同じフォルダ)
分割したいPDFをフォルダに保存します。
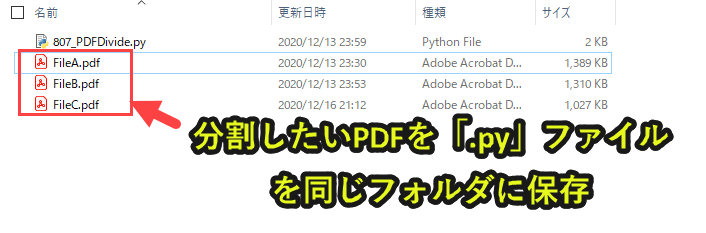
Pythonファイル「.py」と同じフォルダにPDFを保存すること
後半で紹介するプログラムをそのまま使用する場合は、「.py」と「.pdf」が同じフォルダでないとエラーが発生します。
フォルダを指定したい場合は、本記事で紹介するプログラムを一部変更する必要がありますので、ご注意ください。
準備2|必要なライブラリをインストール
今回は以下の2つのライブラリをインストールします。
pip install PyPDF2
PDFを操作し分割するために使用するライブラリです。
上記をインストールしておかないと動かないので、注意が必要です。
Pythonプログラム解説
この記事で紹介するプログラムを解説しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# プログラム1|ライブラリ設定 import PyPDF2 import pathlib import os # プログラム2|フォルダ内のPDFを全て取得 curdir = os.getcwd() files = list(pathlib.Path(curdir).glob('*.pdf')) # プログラム3|フォルダ内の全てのPDFを処理 for file in files: # プログラム4|分割したPDFを保管するためのフォルダ作成 filename = file.name foldername = filename.replace('.pdf','') path = os.path.join(curdir, foldername) if not os.path.isdir(path): os.makedirs(path) # プログラム5|PDFを分割 pdf = PyPDF2.PdfFileReader(filename) for page in range(pdf.numPages): newpdf = PyPDF2.PdfFileWriter() newpdf.addPage(pdf.getPage(page)) # プログラム6|分割したPDFに名前を付けて保存 pageNo = format(page, '0>3') newfilename = os.path.join(path, f'{filename}_{pageNo}.pdf') with open(newfilename, 'wb') as f: newpdf.write(f) |
以下で詳しく説明しています。
プログラム1|ライブラリの設定
|
1 2 3 4 |
# プログラム1|ライブラリ設定 import PyPDF2 import pathlib import os |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
import PyPDF2 |
PyPDF2はPDF操作で使います。
|
3 |
import pathlib |
pathlibはフォルダ内の全PDFを取得するときに使います。
|
4 |
import os |
osはフォルダ指定で使います。
プログラム2|フォルダ内のPDFを全て取得
|
1 2 3 |
# プログラム2|フォルダ内のPDFを全て取得 curdir = os.getcwd() files = list(pathlib.Path(curdir).glob('*.pdf')) |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
curdir = os.getcwd() |
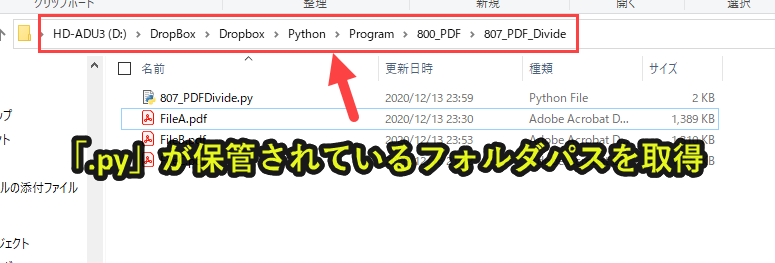
「.py」ファイルが保管されているフォルダをcurdirとして取得します。
|
1 2 |
curdir = os.getcwd() print(curdir) |
実行結果
|
1 |
>>>D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide |
「os.getcwd()」で「.py」ファイルが保管されているフォルダを取得できます。
|
3 |
files = list(pathlib.Path(curdir).glob('*.pdf')) |
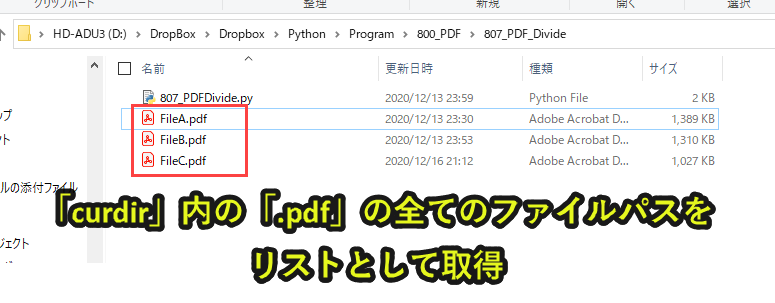
curdirのフォルダ内で、拡張子が「.pdf」のファイルをfilesとして取得します。
|
1 2 |
files = list(pathlib.Path(curdir).glob('*.pdf')) [print(file) for file in files] |
実行結果
|
1 2 3 |
>>>D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide\FileA.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide\FileB.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide\FileC.pdf |
「files」で「.py」ファイルが保管されているフォルダ内の「.pdf」を全て取得できます。
なお、フルパスで取得します。
プログラム3|フォルダ内の全てのPDFを処理
|
1 2 |
# プログラム3|フォルダ内の全てのPDFを処理 for file in files: |
filesには以下の3つのファイルパスが格納されています。(プログラム2)
file[1]=’D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide\FileB.pdf’
file[2]=’D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide\FileC.pdf’
この3つのファイルに対して、一つずつ処理を行います。
なお本記事では3つのファイルを保管しているファルダを事例としているので3つのファイルですが、フォルダに保管されているPDFを全て処理させることができます。
要はファイルが10コあれば、10コ処理してくれます。
プログラム4|結合先のPDFを新規作成
|
1 2 3 4 5 6 |
# プログラム4|分割したPDFを保管するためのフォルダ作成 filename = file.name foldername = filename.replace('.pdf','') path = os.path.join(curdir, foldername) if not os.path.isdir(path): os.makedirs(path) |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
filename = file.name |
file.nameでファイル名を取得することができます。
|
1 |
[print(file.name) for file in files] |
実行結果
|
1 2 3 |
>>>FileA.pdf >>>FileB.pdf >>>FileC.pdf |
このように「file.name」でファイル名を取得することができます。
ここで取得したファイル名は、フォルダ作成のときに使用します。
ただしフォルダ名にするには「.pdf」が邪魔なので、次のプログラムで「.pdf」を除去します。
|
3 |
foldername = filename.replace('.pdf','') |
「filename.replace(‘.pdf’,”)」で「.pdf」を削除します。
|
1 2 3 4 |
for file in files: filename = file.name foldername = filename.replace('.pdf','') print (foldername) |
実行結果
|
1 2 3 |
>>>FileA >>>FileB >>>FileC |
これで「.pdf」を除去することで、フォルダ名として使用することができます。
|
4 |
path = os.path.join(curdir, foldername) |
「FileA」、「FileB」、「FileC」といった名前ではなく、フルパスでないとフォルダを作成できません。
そこで「os.path.join()」を使ってフルパスを作成します。
「os.path.join(A,B)」でAとBを結合してフォルダパスを作成できます。
|
1 2 3 4 5 |
for file in files: filename = file.name foldername = filename.replace('.pdf','') path = os.path.join(curdir, foldername) print (path) |
実行結果
|
1 2 3 |
>>>D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide\FileA >>>D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide\FileB >>>D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide\FileC |
このフォルダパスを使って、以下のプログラムでフォルダを作成します。
しかし既に存在する名前のパスを作成したら困るので、if文を使って同じ名前のフォルダが存在するかどうかをチェックします。
|
5 |
if not os.path.isdir(path): |
このプログラムで、「もしpathで指定したのと同じフォルダが存在しなければ」というif文で検証します。
もし同じ名前のフォルダがなければ次のプログラムでフォルダを作成します。
|
6 |
os.makedirs(path) |
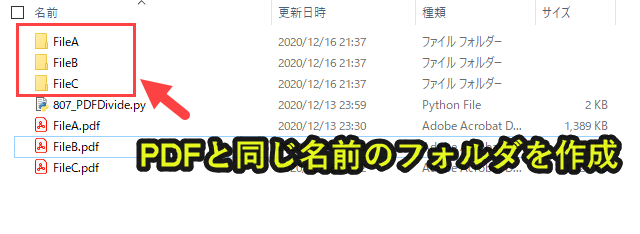
このようにPDFと同じ名前のフォルダを作成します。
プログラム5|PDFを分割
|
1 2 3 4 5 |
# プログラム5|PDFを分割 pdf = PyPDF2.PdfFileReader(filename) for page in range(pdf.numPages): newpdf = PyPDF2.PdfFileWriter() newpdf.addPage(pdf.getPage(page)) |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
pdf = PyPDF2.PdfFileReader(filename) |
filename(プログラム4)で指定したPDFを読み込んで、pdfという変数で扱うようにします。
|
3 |
for page in range(pdf.numPages): |
このプログラムでfor文を使い、pdfを1ページずつ読み込んでいきます。
読み込んだ1ページ1ページはpageという変数で扱います。
|
4 |
newpdf = PyPDF2.PdfFileWriter() |
newpdfという変数を設定し、PDF(書き込み用)を新しく生成します。
このnewpdfはまっさらなPDFと思っていただけると分かりやすいです。
|
5 |
newpdf.addPage(pdf.getPage(page)) |
newpdfにpageを入れていきます。
まっさらなnewpdfにpageをaddPageで入れ込んでいきます(1ページだけ)
最後にプログラム6でnewpdfを名前を付けて保存します。
プログラム6|分割したPDFに名前を付けて保存
|
1 2 3 4 5 |
# プログラム6|分割したPDFに名前を付けて保存 pageNo = format(page, '0>3') newfilename = os.path.join(path, f'{filename}_{pageNo}.pdf') with open(newfilename, 'wb') as f: newpdf.write(f) |
プログラム解説
以下で一行ずつプログラムを解説します
|
2 |
pageNo = format(page, '0>3') |
pageNoに3桁で0埋めした数字を設定します。
3桁で0埋めとは、以下のことを指します。
プログラム
|
1 2 3 4 |
pages= 5 for page in range(pages): pageNo = format(page, '0>3') print (pageNo) |
実行結果
|
1 2 3 4 5 |
>>>001 >>>002 >>>003 >>>004 >>>005 |
一方で0埋めしないと0が付きません。
プログラム
|
1 2 3 |
pages= 5 for page in range(pages): print (page) |
実行結果
|
1 2 3 4 5 |
>>>1 >>>2 >>>3 >>>4 >>>5 |
0埋めをする理由は、以下の記事のようにPDFを結合するときに、順番が意図しない並び方をしてしまうことがあるからです。
期待する並び順
|
1 2 3 4 5 6 7 8 9 10 11 |
>>>1 >>>2 >>>3 >>>4 >>>5 >>>6 >>>7 >>>8 >>>9 >>>10 >>>11 |
実際の並び順
|
1 2 3 4 5 6 7 8 9 10 11 |
>>>1 >>>10←ここじゃない >>>11←ここじゃない >>>2 >>>3 >>>4 >>>5 >>>6 >>>7 >>>8 >>>9 |
0埋めすると並び順を固定できる
|
1 2 3 4 5 6 7 8 9 10 11 |
>>>01 >>>02 >>>03 >>>04 >>>05 >>>06 >>>07 >>>08 >>>09 >>>10←OK >>>11←OK |
このような並び順による影響を防ぐために0埋めを行います。
|
3 |
newfilename = os.path.join(path, f'{filename}_{pageNo}.pdf') |
「os.path.join(A, B)」でAとBを結合して新しいフォルダパスを作成します。
「f'{filename}_{pageNo}.pdf’」と記載することで、「filename(プログラム4)_pageNo(0埋めしたpage番号).pdf」という名前のファイル名を作成できます。
|
1 2 3 4 5 6 7 |
pages= 5 path = 'D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide\FileA' filename = 'FileA' for page in range(pages): pageNo = format(page, '0>3') newfilename = os.path.join(path, f'{filename}_{pageNo}.pdf') print (newfilename) |
実行結果
|
1 2 3 4 5 |
>>>D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide\FileA\FileA.pdf_000.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide\FileA\FileA.pdf_001.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide\FileA\FileA.pdf_002.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide\FileA\FileA.pdf_003.pdf >>>D:\DropBox\Dropbox\Python\Program\800_PDF\807_PDF_Divide\FileA\FileA.pdf_004.pdf |
ここではrangeは0,1,2,3,4となるため、0~4のファイル名となっています。
ここで設定したnewfilenameにnewpdf(プログラム5)をのせます。
|
4 |
with open(newfilename, 'wb') as f: |
newfilenameで設定した新しいPDF名をwb(write binary)モードで開き、そのファイルをfという変数とします。
wbを指定すると、open関数は指定したパスのファイルを新規作成してファイルを開きます。
なお指定したパス(newfilename)のファイルが既に存在する場合は、そのファイルの中身を空にしてファイルを開きますので注意が必要です。
要は同じフォルダあれば、上書きされます。
|
5 |
newpdf.write(f) |
newpdf(プログラム4)をfに書き込みます。
こうすることでPDFを1ページずつ分割することができます。
実際に、フォルダを開いてみると以下のようにPDFが分割して保存されています。
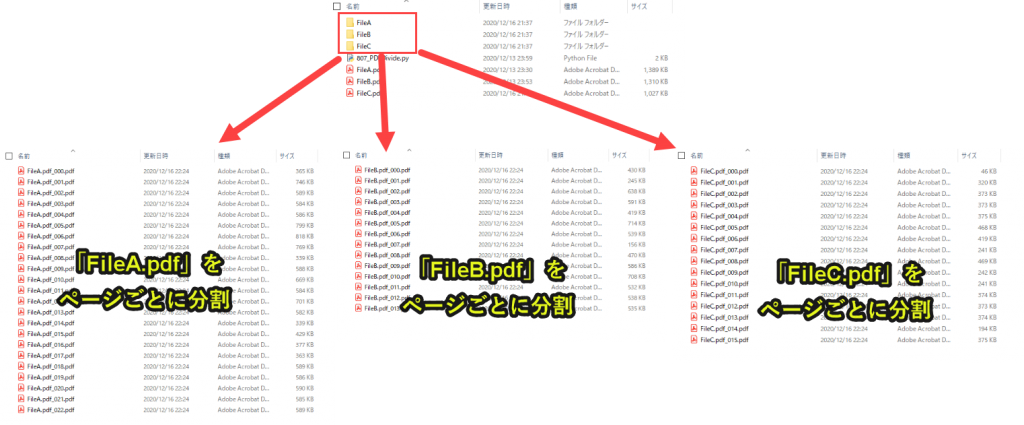
プログラムの解説はここまでです。
Pythonについて詳しく理解したいなら
Pythonを活用すると、仕事を効率化できる幅を広げることができます。
たとえば私が実際にPythonを活用して効率化してきた作業は以下の記事で紹介しています。
興味がある人は以下の記事もご覧ください。
Python×効率化のサンプル
Pythonで効率化できる事例をサンプルコード付きで紹介しています。

Python×Excel
PythonとExcelで自動化できることを紹介しています。
事例も数多く紹介しているので、ぜひ参考にしてみてください。

Pythonって難しい?
Pythonの難易度などについては、以下で紹介しています。
勉強の参考になれば幸いです。
