
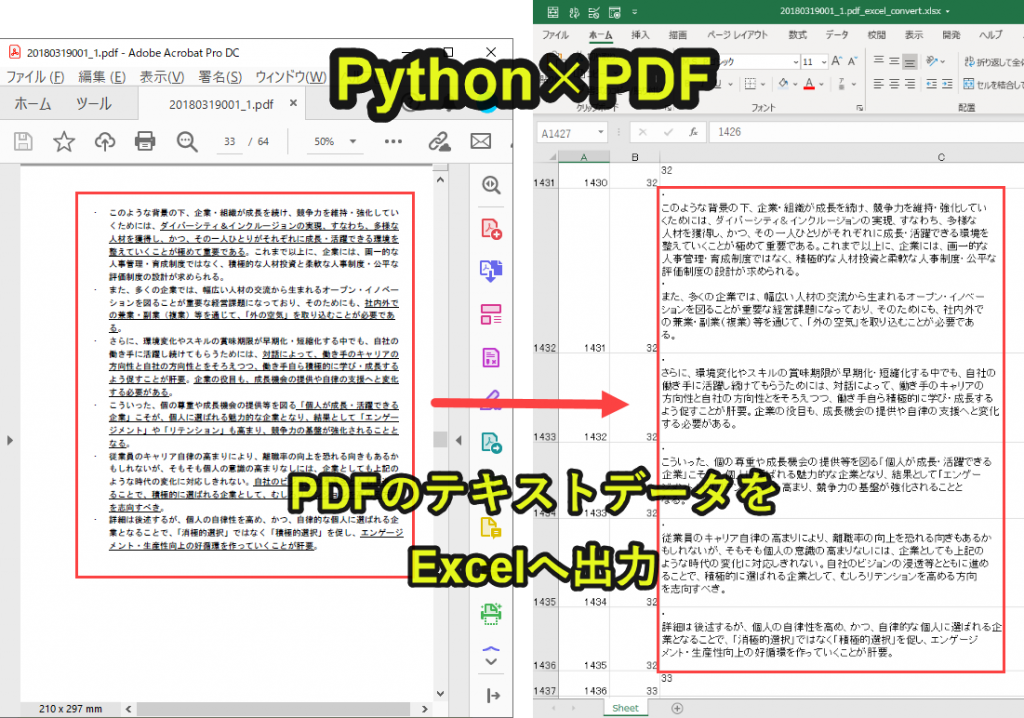
Pythonを使うとPDFのテキストデータを読み込んでExcelに一覧にすることが可能です。
ここでは実務の事例として、PDFをもとにExcelに書き込んでいくPythonプログラムを紹介します。ただしプログラムの性質上、欠点もあります。
この記事では以下についてお伝えしていきます。
・必要なライブラリ
・本プログラムの長所と短所
それでは以下で詳しく紹介していきます。
目次
PythonでPDFを読み込んでテキスト情報をExcelに変換する
今回は以下の作業をpythonで行うことを目指します。
1. テキスト情報を取得したいPDFを読み込む
2. テキストのまとまり(ブロック)ごとにExcelに書き込む

上記のように、PDFのテキスト情報をExcelに転記していきます。
詳しいプログラム解説は後半で行います。
Pythonプログラムを実行するための準備
1. テキストを取得したいPDFの準備
2. 必要なライブラリをインストール
準備1|テキストを取得したいPDFの準備
今回は経済産業省の報告書である、人材力強化の報告書をPDFに書き落としていきます。
上記は目次ですが、全部で64ページありテキストは以下のようにぎっちり記載されています。

このPDFのテキストデータをExcelに書き込んでいきます。
準備2|必要なライブラリをインストール
今回は以下の2つのライブラリをインストールします。
pip install pymupdf
PDFのテキストを取得するためのライブラリです。
pip install openpyxl
Excelへ書き出ためのライブラリです。
上記をインストールしておかないと動かないので、注意が必要です。
Pythonプログラム解説
この記事で紹介するプログラムを解説しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# プログラム1|ライブラリ設定 import fitz import openpyxl as px from openpyxl.styles import Alignment # プログラム2|PDFテキストを格納するリスト作成 item_list = [] # プログラム3|PDFファイルを開く filename = '20180319001_1.pdf' doc = fitz.open(filename) # プログラム4|PDFを1ページずつテキストを取得 for page in range(len(doc)): textblocks = doc[page].getText('blocks') for textblock in textblocks: if textblock[4].isspace() == False: item_list.append([page,textblock[4]]) # プログラム5|新しいエクセルを作成 wb = px.Workbook() ws = wb.active # プログラム6|エクセルの書式設定 myalignment=Alignment(wrap_text=True, shrink_to_fit=False,) ws.column_dimensions['C'].width = 100 # プログラム7|エクセルのヘッダーを出力 headers = ['No', 'ページ', '内容'] for i, header in enumerate(headers): ws.cell(row=1, column=1+i, value=headers[i]) # プログラム8|エクセルにPDFのテキストデータを出力 for y, row in enumerate(item_list): ws.cell(row= y+2, column= 1, value= y+1) for x, cell in enumerate(row): ws.cell(row= y+2, column= x+2, value=item_list[y][x]) ws.cell(row= y+2, column= x+2).alignment = myalignment # プログラム9|エクセルファイルの保存 excelname = f'{filename}_excel_convert.xlsx' wb.save(excelname) |
以下で詳しく説明しています。
プログラム1|ライブラリの設定
|
1 2 3 4 |
# プログラム1|ライブラリの設定 import fitz import openpyxl as px from openpyxl.styles import Alignment |
このライブラリでPDFのテキストを取得します。
Excelを操作するためのopenpyxlです。pxという短縮形で呼び出すようにします。
openpyxlの一部ですが、Excelの列の幅を変更するときに使います。
プログラム2|PDFテキストを格納するリスト作成
|
1 2 |
# プログラム2|PDFテキストを格納するリスト作成 item_list = [] |
item_listというリストを作成します。
このリストにPDFのテキストデータを格納していきます。(詳細はプログラム4)
プログラム3|PDFファイルを開く
|
1 2 3 |
# プログラム3|PDFファイルを開く filename = '20180319001_1.pdf' doc = fitz.open(filename) |
以下でプログラムを解説します。
「.py」ファイルと同じフォルダ内の「20180319001_1.pdf」という名前のPDFを開きます。
今回は経済産業省の報告書である、人材力強化の報告書をPDFに書き落としていきます。
上記は目次ですが、全部で64ページありテキストは以下のようにぎっちり記載されています。

PDFを開いて、その情報をdocとします。
プログラム4|PDFを1ページずつテキストを取得
|
1 2 3 4 5 6 |
# プログラム4|PDFを1ページずつテキストを取得 for page in range(len(doc)): textblocks = doc[page].getText('blocks') for textblock in textblocks: if textblock[4].isspace() == False: item_list.append([page,textblock[4]]) |
このプログラムがPDFのテキストを取得する部分です。
以下でプログラムを解説します。
プログラム3で取得したdoc(対象PDF)を1ページずつ処理していきます。
今回対象としたPDFは64ページあるので、1ページ目から64ページ目まで処理を行います。
変数textblocksに、そのページの’blocks’という単位ごとにテキストを格納していきます。
たとえばPDF24ページは、textblocksの二次元配列は以下のような値となります。
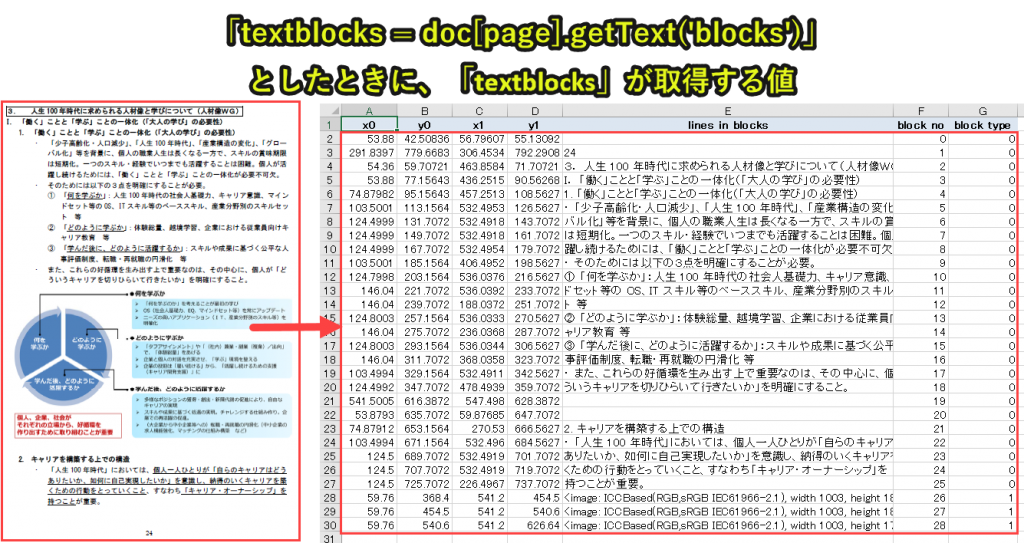
上の画像のデータについて、各列の意味を記載します。
・lines in blocks(Excel画像のE列)|テキスト情報
・block no(Excel画像のE列)|要素番号
・block type (Excel画像のE列)|0はテキスト、1は画像を示す
すなわち、本事例の24ページ目は、0~28の要素(F列)から成り、テキストデータは26コ、画像データは3コです。
そして最も重要なテキスト情報はE列に存在するため、リストで言うと5番目の値となります。
(x0, y0, x1, y1の情報はそこまで重要ではないので、触れません)
textblocksをfor文を使い、一つずつ処理していきます。
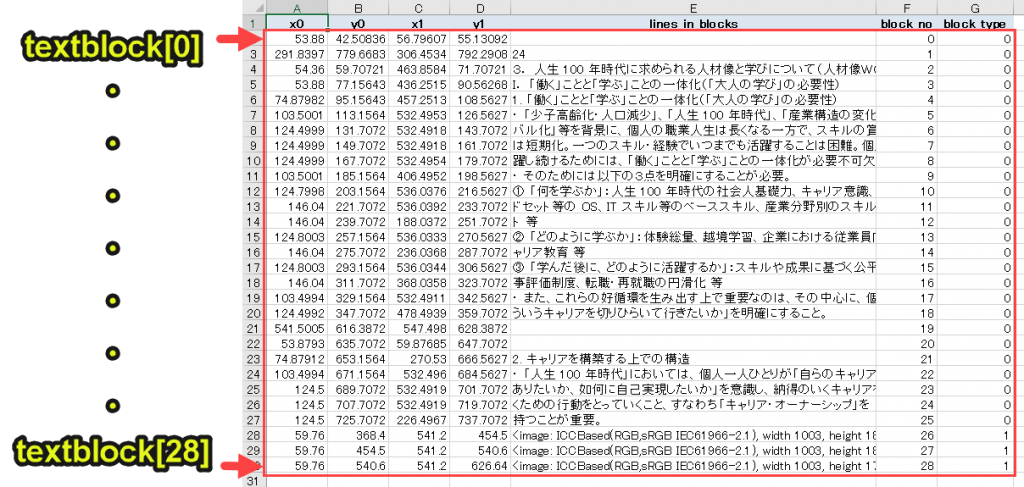
textblockの4番目の値がテキストデータです。
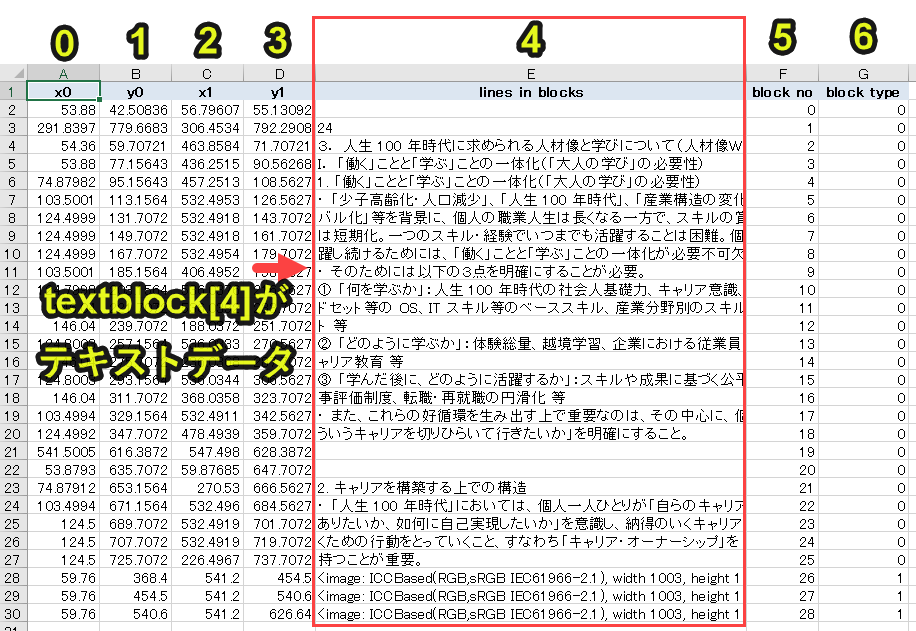
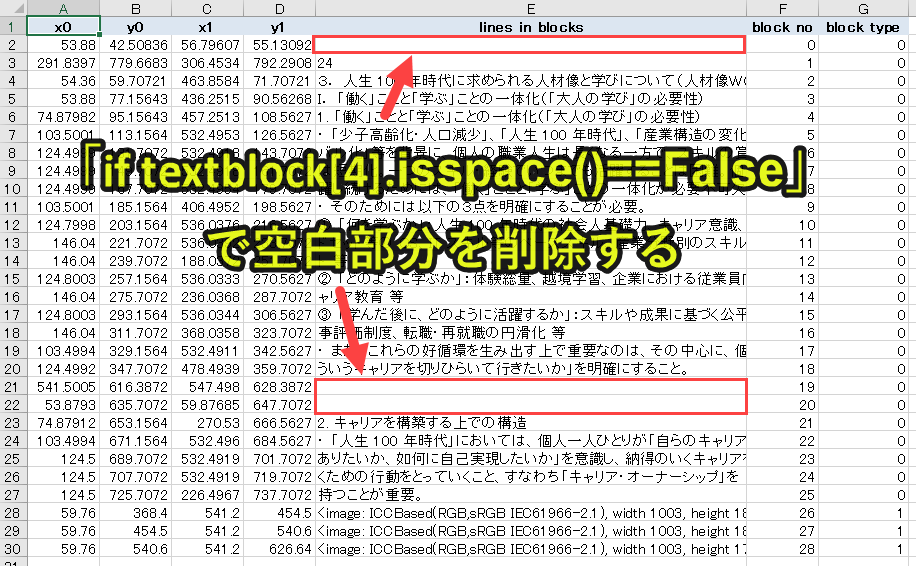
textblock[4]をよく見ると、空白で何もデータが格納されていない箇所があります。
そこで、textblock[4].isspace()がFalse、つまりテキストデータが存在せず、改行や空白スペースであれば、取り除くように処理を組んでいます。
プログラム2で作成したitem_listに2つの要素を追加します。
要素1はpage(ページ番号)、要素2はテキストデータです。
この2つの情報をExcelに書き出していきます。(プログラム5以降)
page(ページ番号)を入れることで、Excelに出力したあとの検索性を向上させます。
プログラム5|新しいエクセルを作成
|
1 2 3 |
# プログラム5|新しいエクセルを作成 wb = px.Workbook() ws = wb.active |
新しいExcelを作成します。
以下でプログラムを解説します。
新しいExcelを作成して、wbとします。
wbの中に、wsという新しいシートを作成します。
このwsにPDFのテキストデータを格納していきます。
プログラム6|エクセルの書式設定
|
1 2 3 |
# プログラム6|エクセルの書式設定 myalignment=Alignment(wrap_text=True, shrink_to_fit=False,) ws.column_dimensions['C'].width = 100 |
Excelの書式を設定します。
以下でプログラムを解説します。
セルの書式をあらかじめ設定しておきます。
・shrink_to_fit=False:セルの幅に合わせて、文字を小さくする機能はOFF(False)
この書式設定はプログラム8で使用します。
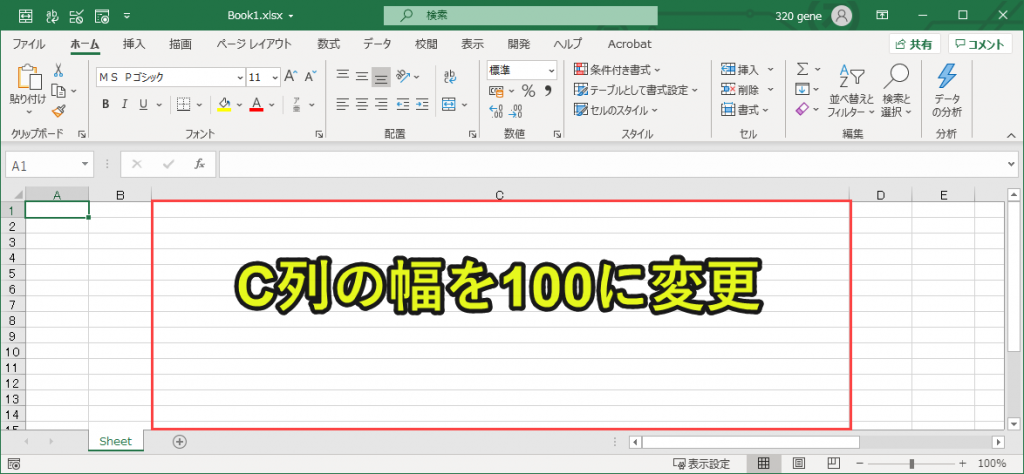
ws(Excelのシート)のC列を100に変更します。もともとの設定より幅を広くしておきます。(必ずしも100である必要はありません。)
理由はC列にテキストを入れていくからです。C列の幅を広げることで、視認性を良くするのが狙いです。
プログラム7|エクセルのヘッダーを出力
|
1 2 3 4 |
# プログラム7|エクセルのヘッダーを出力 headers = ['No', 'ページ', '内容'] for i, header in enumerate(headers): ws.cell(row=1, column=1+i, value=headers[i]) |
Excelにヘッダー情報を出力します。
以下でプログラムを解説します。
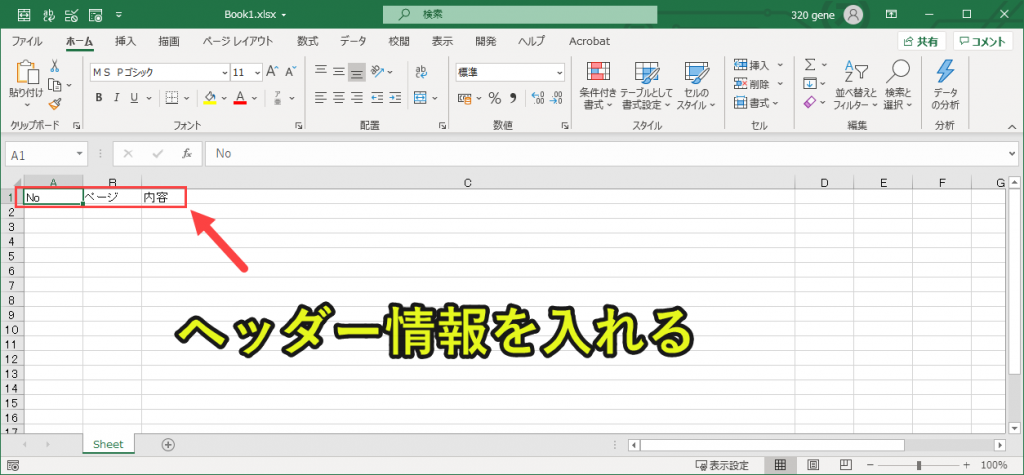
headersというリストに3つの要素[‘No’,’ページ’, ‘内容’]を入れます。
・ページ:もともとのPDFのページ番号(PDFを確認したいときに番号があると便利)
・内容:PDFのテキスト
上記の3つを格納していくので、そのヘッダーを出力しておきます。
「enumerate()」で、リストのインデックス番号を要素を取得することが可能
たとえば、list=[‘a’,’b’,’c’]のとき
|
1 2 |
for i, name in enumerate(list): print(i, name) |
結果は以下のようになる。
|
1 2 3 |
>>>0 a >>>1 b >>>2 c |
インデックス番号とセルのアドレスを紐づけることで、リストをエクセルに出力するときに重宝します。
ws(新しいシート)の1行目(row=1)の(1+i)列目に、headers[i]の値を出力します。
結果的にwsの1行目に、以下のように出力されます。
プログラム8|エクセルにPDFのテキストデータを出力
|
1 2 3 4 5 6 |
# プログラム8|エクセルにPDFのテキストデータを出力 for y, row in enumerate(item_list): ws.cell(row= y+2, column= 1, value= y+1) for x, cell in enumerate(row): ws.cell(row= y+2, column= x+2, value=item_list[y][x]) ws.cell(row= y+2, column= x+2).alignment = myalignment |
Excelにデータを格納していきます。
以下でプログラムを解説します。
enumerateを使うと、リストの内容をExcelに書き出すときに便利です。
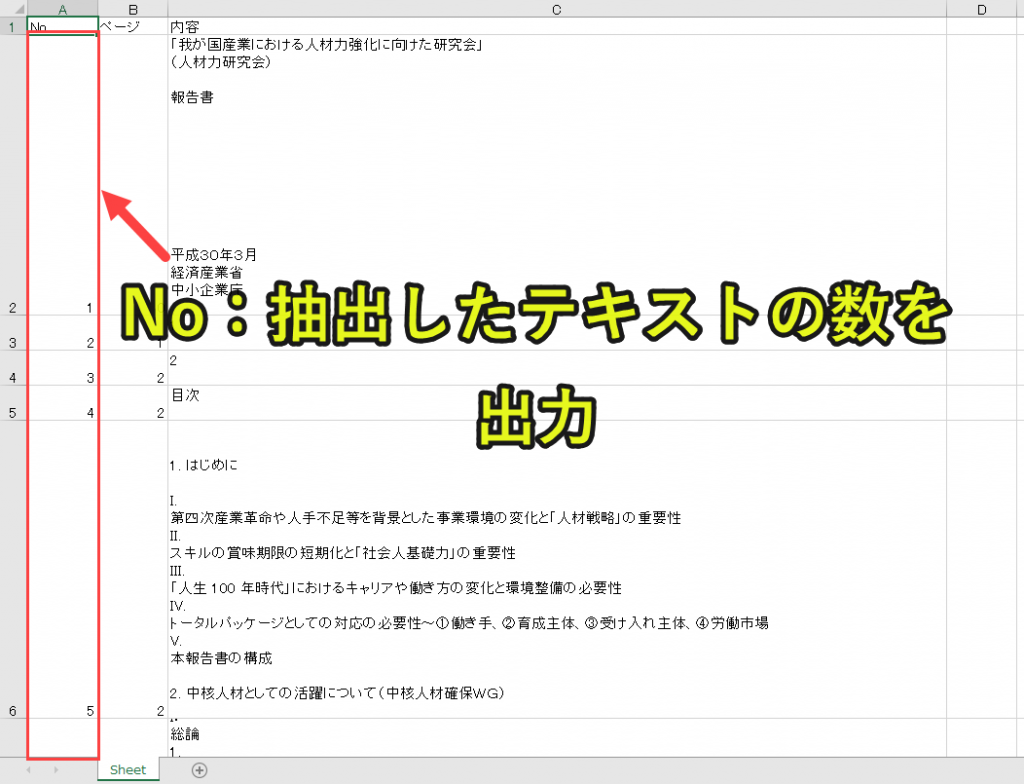
ws(新しいシート)の(y+2)行目、1列目(A列)に(y+1)の値を入れていきます。
二次元リストの値をExcelに書き出すときは、この記載のようにenumerateを二段階で実行すると便利です。
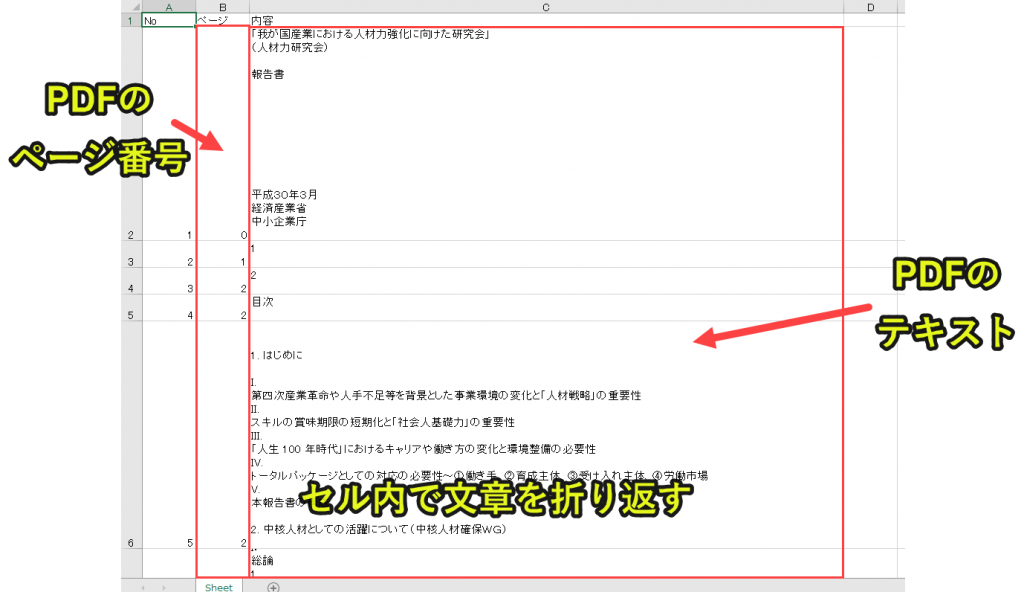
ws(新しいシート)の(y+2)行目、x+2列目(B列とC列)にitem_list[y][x]の値を入れていきます。
ws(新しいシート)の(y+2)行目、x+2列目(B列とC列)の書式をmyalignmentにします。(プログラム6で設定)
プログラム9|エクセルファイルの保存
|
1 2 3 |
# プログラム9|エクセルファイルの保存 excelname = f'{filename}_excel_convert.xlsx' wb.save(excelname) |
Excelを保存します。
以下でプログラムを解説します。
ファイル名を指定します。
今回の事例では、filename(プログラム2)が「’20180319001_1.pdf’」なので、以下のようになります。
上記のファイル名で保管されます。
指定したファイル名で保管します。
保管先は、.pyファイルが保管されているフォルダと同じところです。

プログラムの解説はここまでです。
本プログラムの注意点
本プログラムでは、PDFのテキストを全て取得することが可能です。
しかし以下のようなことができない可能性があります。
・余計な改行が入っている
・セルに入っている文章の切れ目が悪い
図の中の文字は取得できない
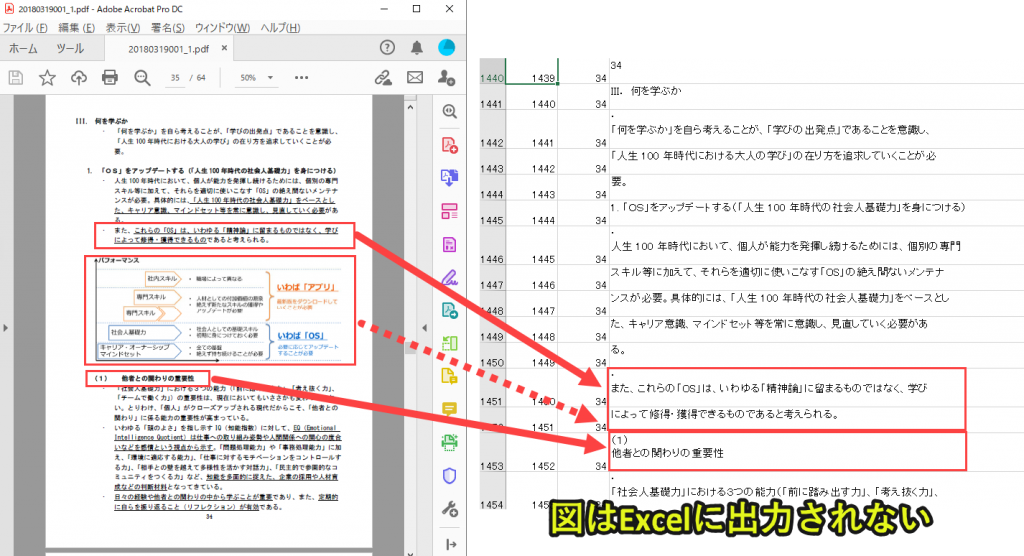
上記の画像のとおり、PDF内の図に表示されている文字を取得できません。
これが本プログラムの限界の一つです。
しかしながら、画像は別のプログラムで取得可能です。
別の記事で紹介予定ですので、PDFの図も取得したい人はそちらをご覧いただくと良いかと思います。
工事中
余計な改行が入っている

書き出しを行ったExcelは余計な改行が入っていることがあります。
これは本プログラムの仕様上、回避が難しいです。
これに対応するには、エクセルに出力した後で、改行を削除するような対処が必要になります。
このままでも内容が分からないわけではないため、このまま対処しないというのも選択肢の一つです
セルに入っている文章の切れ目が悪い
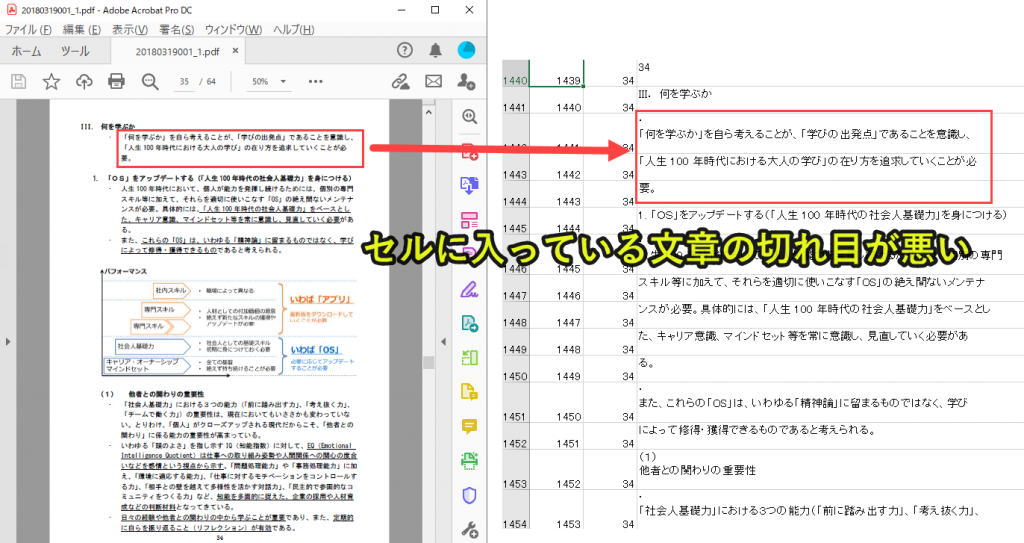
セルに入る文章は、PDFの文章の切れ目に依存します。
したがってPDFの改行がそのまま反映されるため、望む形でExcelに出力されない場合があります。
デメリットは費用対効果で考える
・余計な改行が入っている
・セルに入っている文章の切れ目が悪い
上記のデメリットがあることを理解した上で、実務で使える形に調整が必要かどうかを判断します。
たとえばExcelに出力したあとで、改行を削除するなどの処理を行うことで対応することも可能です。
実際、私はExcelに一覧にした後に、作業を誰かに依頼する方法も可能です。
そのようなときは以下のように作業を行っています。
2. 確認作業を人に依頼(改行削除、元PDFの抜けがないこと)
3. 修正作業を人に依頼
PDFのボリュームにもよりますが、これで人に作業をお願いすることができます。
ゼロから転記作業を依頼するより、コストも時間もかからないので、オススメの方法です。
作業を人に依頼することで、今回のような64ページもあるPDFをマウスを使って一つずつコピペするよりラクなはずです。
最終的な資料の精度などを含めて、費用対効果次第では活用を検討するのがオススメです。
Pythonについて詳しく理解したいなら
Pythonを活用すると、仕事を効率化できる幅を広げることができます。
たとえば私が実際にPythonを活用して効率化してきた作業は以下の記事で紹介しています。
興味がある人は以下の記事もご覧ください。
Python×効率化のサンプル
Pythonで効率化できる事例をサンプルコード付きで紹介しています。

Python×Excel
PythonとExcelで自動化できることを紹介しています。
事例も数多く紹介しているので、ぜひ参考にしてみてください。

Pythonって難しい?
Pythonの難易度などについては、以下で紹介しています。
勉強の参考になれば幸いです。
