
Pythonのウェブスクレイピングに関するウェブ情報は、数多く紹介されています。
しかし、ちょっとモノ足りないと感じることがあります。
理由1|基本的な情報が多い
理由2|仕事でどう活用すればいいのかイメージがわかない
理由3|実例を使った内容を知りたい
そこで、この記事ではYahooオークションのデータをPythonで取得することにしました。
・YahooAuctionのデータ取得からExcel出力までプログラムを紹介
・プログラム解説や仕事での応用方法
Pythonを体験したい人は、コピペしてプログラムをそのまま使ってみてください。
目次
PythonでYahooAuctionのデータ取得してExcelに出力してみた
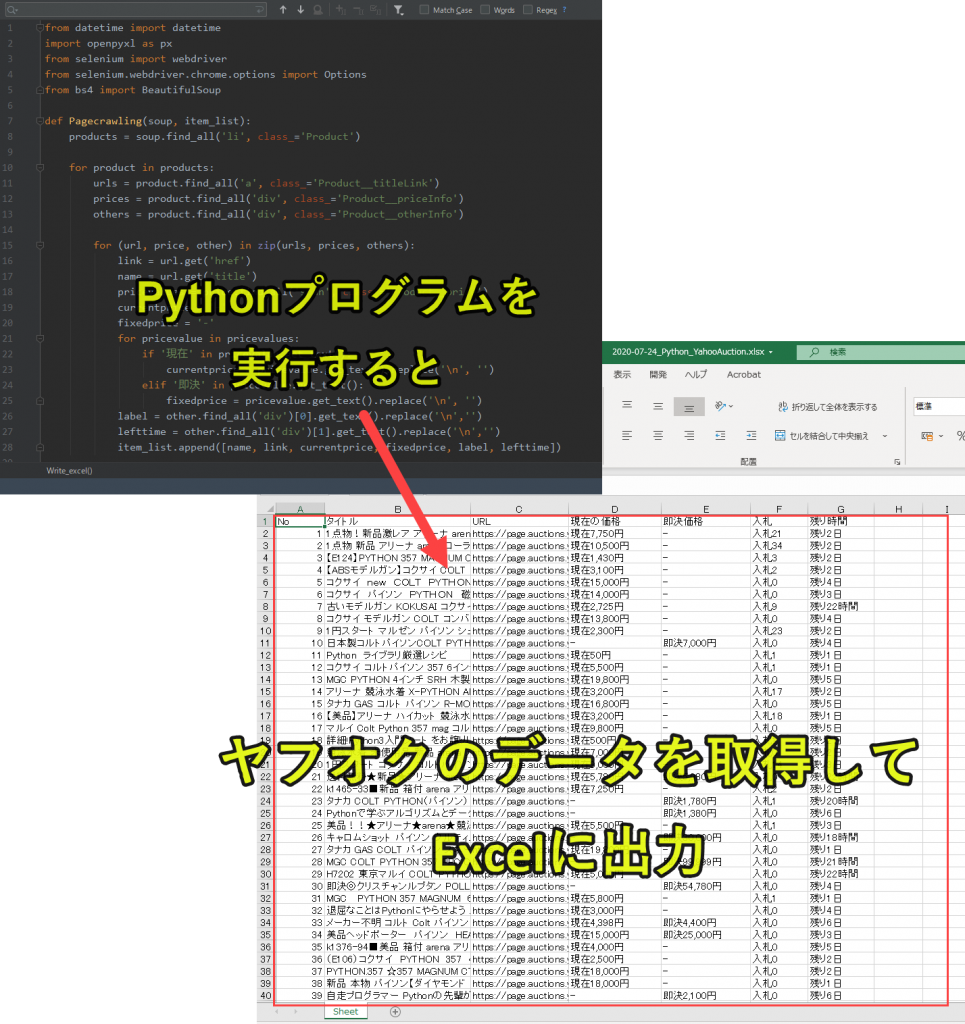
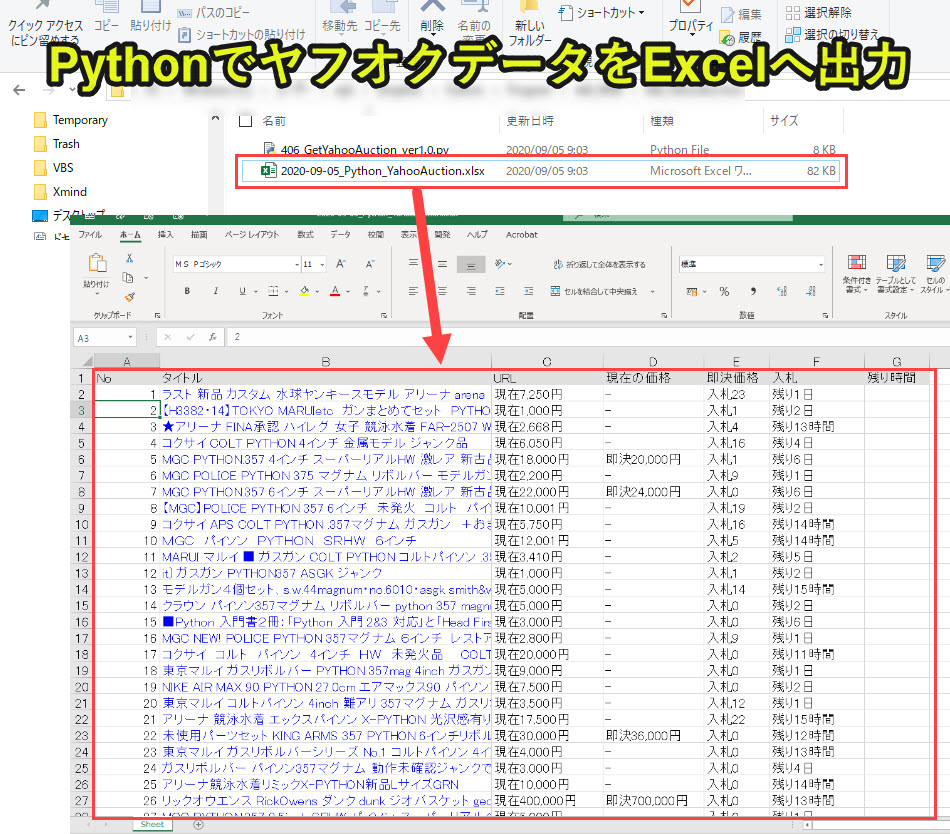
この記事で紹介しているプログラムを実行したときの結果を以下に示します。
ここでは、Yahooオークションで「Python」と検索した場合に得られる結果をExcelにリスト化しています。
Pythonプログラムを動かす前の事前準備
本記事のプログラムを実行する前に、以下の3つのライブラリをインストールしておく必要があります。
・openpyxl(Excel操作のため)
・requests(web情報取得のため)
・bs4(web情報の週出のため)
準備|必要ライブラリのインストール
pip install openpyxl
このライブラリはExcelに出力するときに使います。
pip install request
このライブラリはYahooオークションのサイトにアクセスして情報を取得するときに使います。
pip install bs4
このライブラリはYahooオークションのサイトに情報を解析するときに使います。
YahooAuctionのデータを取得するプログラム
Pythonプログラムを以下に記載しているので、そのままコピペして使用することが可能です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 |
#プログラム1|ライブラリ設定 from datetime import datetime import openpyxl as px from openpyxl.styles import PatternFill import requests from bs4 import BeautifulSoup #プログラム2|ヤフオクページから情報をスクレイピング def Pagecrawling(soup, item_list): # プログラム2-1|<li>タグのなかで、class='Product'のものを変数productsに格納 products = soup.find_all('li', class_='Product') # プログラム2-2|変数productsの要素を一つずつ調査 for product in products: # プログラム2-3|変数productsのなかで、aタグで、class='Product__titleLink'のものを変数urlsに格納 urls = product.find_all('a', class_='Product__titleLink') # プログラム2-4|変数productsのなかで、divタグで、class='Product__priceInfo'のものを変数pricesに格納 prices = product.find_all('div', class_='Product__priceInfo') # プログラム2-5|変数productsのなかで、divタグで、class='Product__otherInfo'のものを変数othersに格納 others = product.find_all('div', class_='Product__otherInfo') # プログラム2-6|zip関数でまとめて繰り返し処理を実行 for (url, price, other) in zip(urls, prices, others): # プログラム2-7|変数linkに変数urlのhref部分を取得(製品url) link = url.get('href') # プログラム2-8|変数nameに変数urlのtitle部分を取得(製品名) name = url.get('title') # プログラム2-9|変数priceのspanタグで、class='Product__price'のものを変数pricevaluesに格納 pricevalues = price.find_all('span', class_='Product__price') # プログラム2-10|変数の初期化 currentprice = '-' fixedprice = '-' # プログラム2-11|変数pricevaluesの要素を一つずつ処理 for pricevalue in pricevalues: # プログラム2-12|もし変数pricevalueのテキスト情報が'現在'が含まれていれば if '現在' in pricevalue.get_text(): # プログラム2-13|変数currentpriceに現在の価格を取得('\n'で改行を削除) currentprice = pricevalue.get_text().replace('\n', '') # プログラム2-14|もし変数pricevalueのテキスト情報が'即決'が含まれていれば elif '即決' in pricevalue.get_text(): # プログラム2-15|変数fixedpriceに即決の価格を取得('\n'で改行を削除) fixedprice = pricevalue.get_text().replace('\n', '') # プログラム2-16|変数labelのdivタグの0番目の要素を取得('\n'で改行を削除)→入札 label = other.find_all('div')[0].get_text().replace('\n','') # プログラム2-17|変数labelのdivタグの1番目の要素を取得('\n'で改行を削除)→残り時間 lefttime = other.find_all('div')[1].get_text().replace('\n','') # プログラム2-18|リスト「item_list」に必要な要素を追加 item_list.append([name, link, currentprice, fixedprice, label, lefttime]) # プログラム2-19|リスト「item_list」を返す return item_list # プログラム3|次へリンクを探す def Checkpage(pagerlinks): # プログラム3-1|変数pageurlをNoneにリセット pageurl = None # プログラム3-2|引数pagerlinksの中に、「次へ」があれば、そのurlをpageurlに設定(「次へ」がない場合は、Noneのまま) for pagerlink in pagerlinks: if pagerlink.get_text() == '次へ': pageurl = pagerlink.get('href') break # プログラム3-3|pageurlを返す return pageurl # プログラム4|エクセルに出力 def Write_excel(item_list, keyword): # プログラム4-1|エクセルを取得 wb = px.Workbook() ws = wb.active # プログラム4-2|エクセルのヘッダーの背景色を設定 fill = PatternFill(patternType='solid', fgColor='e0e0e0', bgColor='e0e0e0') # プログラム4-3|エクセル1行目のヘッダーを出力 headers = ['No', 'タイトル', 'URL', '現在の価格','即決価格','入札','残り時間'] for i, header in enumerate(headers): ws.cell(row=1, column=1+i, value=headers[i]) ws.cell(row=1, column=1+i).fill = fill # プログラム4-4|エクセル2行目以降のデータを出力 for y, row in enumerate(item_list): ws.cell(row= y+2, column= 1, value= y+1) for x, cell in enumerate(row): if x == 0: ws.cell(row= y+2, column= x+2, value=item_list[y][x]) elif x == 1: ws.cell(row= y+2, column= x+1).hyperlink = item_list[y][x] ws.cell(row= y+2, column= x+1).font = px.styles.fonts.Font(color='0000EE') else: ws.cell(row= y+2, column= x+1, value=item_list[y][x]) # プログラム4-5|日付を取得 now = datetime.now() hiduke = now.strftime('%Y-%m-%d') # プログラム4-6|エクセルファイルの保存 filename = hiduke + '_' + keyword + '_' +'YahooAuction.xlsx' wb.save(filename) #プログラム5|mainプログラム # プログラム5-1|検索キーワードとYahooオークションURLの設定 keyword = 'Python' url = 'https://auctions.yahoo.co.jp/search/search?p=' + keyword + '&n=100'; # プログラム5-2|ヤフオクページの取得 r = requests.get(url) soup = BeautifulSoup(r.text, 'lxml') # プログラム5-3|取得したデータを格納するリスト item_list = [] # プログラム5-4|リスト「item_list」にプログラム3の結果を格納 item_list = Pagecrawling(soup, item_list) # プログラム5-5|プログラム4を実行して、次のページがあるかどうか調査 pageurl = Checkpage(soup.find_all('a', class_='Pager__link')) # プログラム5-6|次のページがなくなるまで、処理を実行 while True: # プログラム5-7|次のページがないならwhile文を終了 if pageurl is None: break # プログラム5-8|次のページがあるなら処理を実行 else: # プログラム5-9|次のページを取得 nextpage = requests.get(pageurl) soup = BeautifulSoup(nextpage.text, 'lxml') # プログラム5-10|リスト「item_list」にプログラム3の結果を格納 item_list = Pagecrawling(soup, item_list) # プログラム5-11|プログラム4を実行して、次のページがあるかどうか調査 pageurl = Checkpage(soup.find_all('a', class_='Pager__link')) # プログラム5-12|リスト「item_list」の中身を調べる [print(i, item) for i, item in enumerate(item_list)] # プログラム5-13|プログラム5を実行して、リスト「item_list」をエクセルに書き出す Write_excel(item_list, keyword) |
以下でプログラムについて解説をしていきます。
プログラム1|ライブラリの設定
|
1 2 3 4 5 |
from datetime import datetime import openpyxl as px from openpyxl.styles import PatternFill import requests from bs4 import BeautifulSoup |
5つのライブラリを設定
・datetime→Excelファイル名の作成
・openpyxl→Excelファイルの操作
・PatternFill→Excelの背景色の変更
・requests→ウェブ情報の取得
・BeautifulSoup→ウェブスクレイピングでデータを抽出
プログラム2|ヤフオクページから情報をスクレイピング
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
def Pagecrawling(soup, item_list): # プログラム2-1|<li>タグのなかで、class='Product'のものを変数productsに格納 products = soup.find_all('li', class_='Product') # プログラム2-2|変数productsの要素を一つずつ調査 for product in products: # プログラム2-3|変数productsのなかで、aタグで、class='Product__titleLink'のものを変数urlsに格納 urls = product.find_all('a', class_='Product__titleLink') # プログラム2-4|変数productsのなかで、divタグで、class='Product__priceInfo'のものを変数pricesに格納 prices = product.find_all('div', class_='Product__priceInfo') # プログラム2-5|変数productsのなかで、divタグで、class='Product__otherInfo'のものを変数othersに格納 others = product.find_all('div', class_='Product__otherInfo') # プログラム2-6|zip関数でまとめて繰り返し処理を実行 for (url, price, other) in zip(urls, prices, others): # プログラム2-7|変数linkに変数urlのhref部分を取得(製品url) link = url.get('href') # プログラム2-8|変数nameに変数urlのtitle部分を取得(製品名) name = url.get('title') # プログラム2-9|変数priceのspanタグで、class='Product__price'のものを変数pricevaluesに格納 pricevalues = price.find_all('span', class_='Product__price') # プログラム2-10|変数の初期化 currentprice = '-' fixedprice = '-' # プログラム2-11|変数pricevaluesの要素を一つずつ処理 for pricevalue in pricevalues: # プログラム2-12|もし変数pricevalueのテキスト情報が'現在'が含まれていれば if '現在' in pricevalue.get_text(): # プログラム2-13|変数currentpriceに現在の価格を取得('\n'で改行を削除) currentprice = pricevalue.get_text().replace('\n', '') # プログラム2-14|もし変数pricevalueのテキスト情報が'即決'が含まれていれば elif '即決' in pricevalue.get_text(): # プログラム2-15|変数fixedpriceに即決の価格を取得('\n'で改行を削除) fixedprice = pricevalue.get_text().replace('\n', '') # プログラム2-16|変数labelのdivタグの0番目の要素を取得('\n'で改行を削除)→入札 label = other.find_all('div')[0].get_text().replace('\n','') # プログラム2-17|変数labelのdivタグの1番目の要素を取得('\n'で改行を削除)→残り時間 lefttime = other.find_all('div')[1].get_text().replace('\n','') # プログラム2-18|リスト「item_list」に必要な要素を追加 item_list.append([name, link, currentprice, fixedprice, label, lefttime]) # プログラム2-19|リスト「item_list」を返す return item_list |
・liタグのProductのクラスから、各製品情報を取得|プログラム2-1
・プログラム2-1からタグとクラスで分解(製品の詳細情報取得のための下準備)|プログラム2-2~2-5
・製品の詳細情報を取得|プログラム2-6~2-17
・「item_list」のりストへ製品の詳細情報を追加|プログラム2-18
・「item_list」をプログラム5へ返す|プログラム2-19

・タイトル|name
・URL|link
・現在の価格|currentprice
・即決価格|fixedprice
・入札|label
・残り時間|lefttime
プログラム3|次へリンクを探す
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
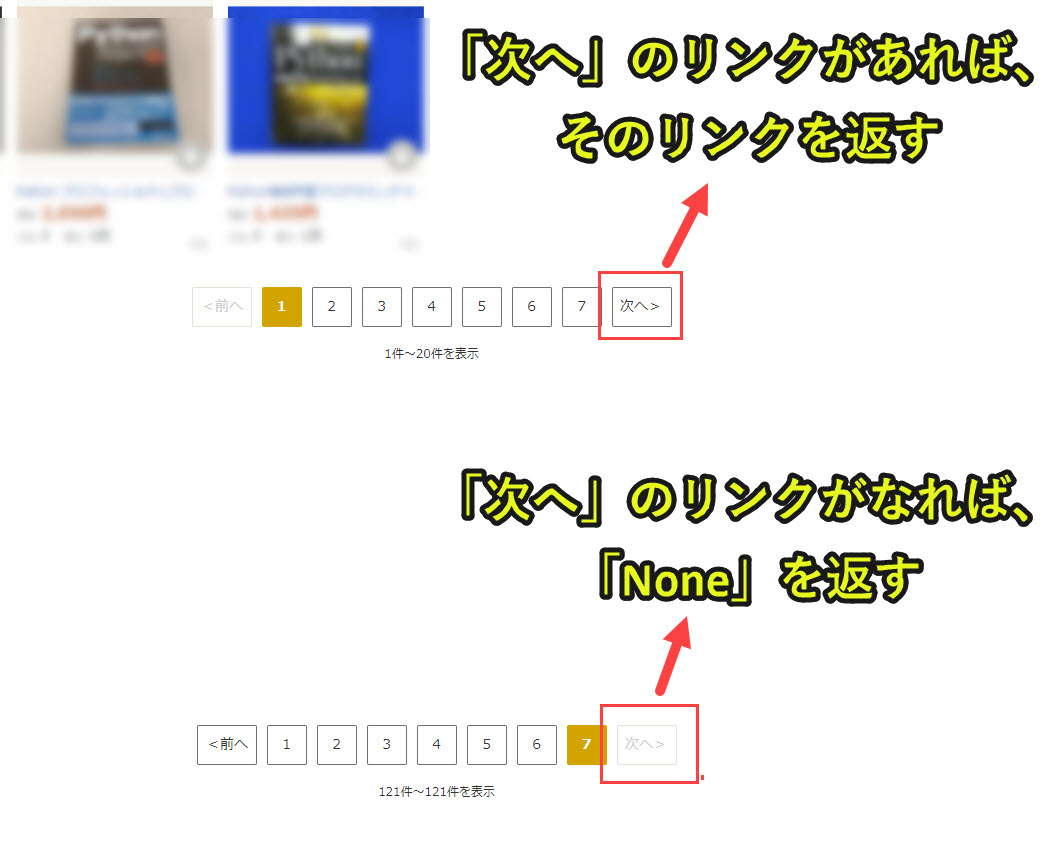
def Checkpage(pagerlinks): # プログラム3-1|変数pageurlをNoneにリセット pageurl = None # プログラム3-2|引数pagerlinksの中に、「次へ」があれば、そのurlをpageurlに設定(「次へ」がない場合は、Noneのまま) for pagerlink in pagerlinks: if pagerlink.get_text() == '次へ': pageurl = pagerlink.get('href') break # プログラム3-3|pageurlを返す return pageurl |
以下でカンタンにプログラムの説明します。
・変数pageurlを「None」にリセットして初期化|プログラム3-1
・プログラム2から受け取ったpagerlinks(ヤフオク内のリンク)を一つずつチェックし、「次へ」のリンクを取得|プログラム3-2
・「pageurl」をプログラム5へ返す|プログラム3-3
プログラム4|エクセルに出力
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
def Write_excel(item_list, keyword): # プログラム4-1|エクセルを取得 wb = px.Workbook() ws = wb.active # プログラム4-2|エクセルのヘッダーの背景色を設定 fill = PatternFill(patternType='solid', fgColor='e0e0e0', bgColor='e0e0e0') # プログラム4-3|エクセル1行目のヘッダーを出力 headers = ['No', 'タイトル', 'URL', '現在の価格','即決価格','入札','残り時間'] for i, header in enumerate(headers): ws.cell(row=1, column=1+i, value=headers[i]) ws.cell(row=1, column=1+i).fill = fill # プログラム4-4|エクセル2行目以降のデータを出力 for y, row in enumerate(item_list): ws.cell(row= y+2, column= 1, value= y+1) for x, cell in enumerate(row): if x == 0: ws.cell(row= y+2, column= x+2, value=item_list[y][x]) elif x == 1: ws.cell(row= y+2, column= x+1).hyperlink = item_list[y][x] ws.cell(row= y+2, column= x+1).font = px.styles.fonts.Font(color='0000EE') else: ws.cell(row= y+2, column= x+1, value=item_list[y][x]) # プログラム4-5|日付を取得 now = datetime.now() hiduke = now.strftime('%Y-%m-%d') # プログラム4-6|エクセルファイルの保存 filename = hiduke + '_' + keyword + '_' +'YahooAuction.xlsx' wb.save(filename) |
以下でカンタンにプログラムの説明します。
・エクセルを作成|プログラム4-1
・プログラム4-1で作成したエクセルの1行目にヘッダー情報を出力|プログラム4-2~4-3
・プログラム2,3,5で取得したデータをエクセルの2行目以降に出力(製品名にはハイパーリンクを付ける)|プログラム4-4
・エクセルを「日付 + ヤフオク検索キーワード.YahooAuction.xlsx」という名前で保存|プログラム4-5~4-6
プログラム5|mainプログラム
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
#プログラム5|mainプログラム # プログラム5-1|検索キーワードとYahooオークションURLの設定 keyword = 'Python' url = 'https://auctions.yahoo.co.jp/search/search?p=' + keyword + '&n=100'; # プログラム5-2|ヤフオクページの取得 r = requests.get(url) soup = BeautifulSoup(r.text, 'lxml') # プログラム5-3|取得したデータを格納するリスト item_list = [] # プログラム5-4|リスト「item_list」にプログラム3の結果を格納 item_list = Pagecrawling(soup, item_list) # プログラム5-5|プログラム4を実行して、次のページがあるかどうか調査 pageurl = Checkpage(soup.find_all('a', class_='Pager__link')) # プログラム5-6|次のページがなくなるまで、処理を実行 while True: # プログラム5-7|次のページがないならwhile文を終了 if pageurl is None: break # プログラム5-8|次のページがあるなら処理を実行 else: # プログラム5-9|次のページを取得 nextpage = requests.get(pageurl) soup = BeautifulSoup(nextpage.text, 'lxml') # プログラム5-10|リスト「item_list」にプログラム3の結果を格納 item_list = Pagecrawling(soup, item_list) # プログラム5-11|プログラム4を実行して、次のページがあるかどうか調査 pageurl = Checkpage(soup.find_all('a', class_='Pager__link')) # プログラム5-12|リスト「item_list」の中身を調べる [print(i, item) for i, item in enumerate(item_list)] # プログラム5-13|プログラム5を実行して、リスト「item_list」をエクセルに書き出す Write_excel(item_list, keyword) |
・検索キーワードでヤフオクページにアクセス|プログラム5-1
・ヤフオクページのウェブデータを取得|プログラム5-2
・「item_list」を作成し、プログラム2でウェブデータ抽出|プログラム5-3~5-4
・次のページがなくなるまで、データ抽出|プログラム5-5~5-11
・「item_list」の中身をチェックしてエディタに出力|プログラム5-12
・プログラム4でエクセルへ出力|プログラム5-13
プログラム5がメインで動きつつ、プログラム2と3でヤフオク情報を収集し、最後にプログラム4でエクセルへ出力する流れです。
プログラムの解説は以上です。
Pythonについて詳しく理解したいなら
Pythonを活用すると、仕事を効率化できる幅を広げることができます。
たとえば私が実際にPythonを活用して効率化してきた作業は以下の記事で紹介しています。
興味がある人は以下の記事もご覧ください。

Pythonの難易度などについては、以下で紹介しています。
勉強の参考になれば幸いです。
