

Pythonを使うと、簡単にウェブからCSVファイルをダウンロードすることができます。
仮にウェブサイトへのログインが必要であっても、ログイン情報を使ってブラウザ操作することで自動でCSVファイルを取得可能です。
さらに良いことは、CSVファイルをダウンロードした後、CSVのデータ解析まで自動化することで、実務を効率化できます。
この記事では、私が実際の業務で使っている「ログインが必要なサイトからCSVファイルするプログラム」と、そのプログラムの業務での活用場面をお伝えします。
・売上データが入った2つのCSVファイルをダウンロード
→(ダウンロード後、そのCSVを解析)
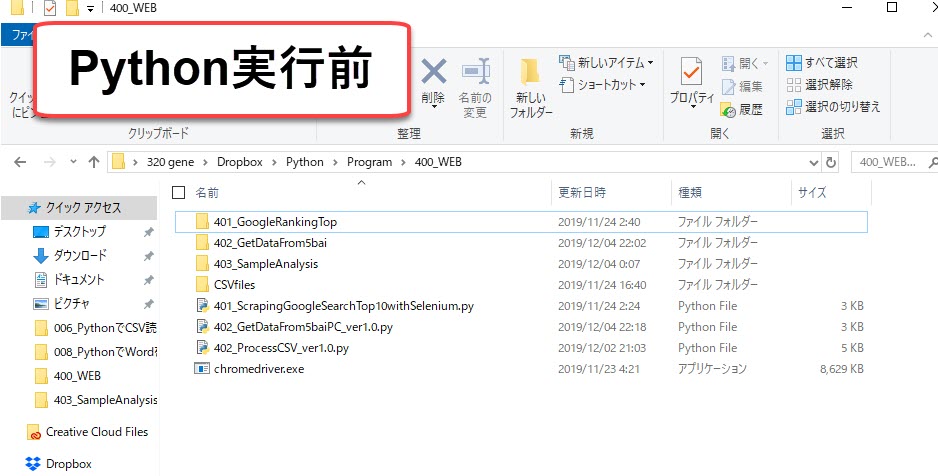
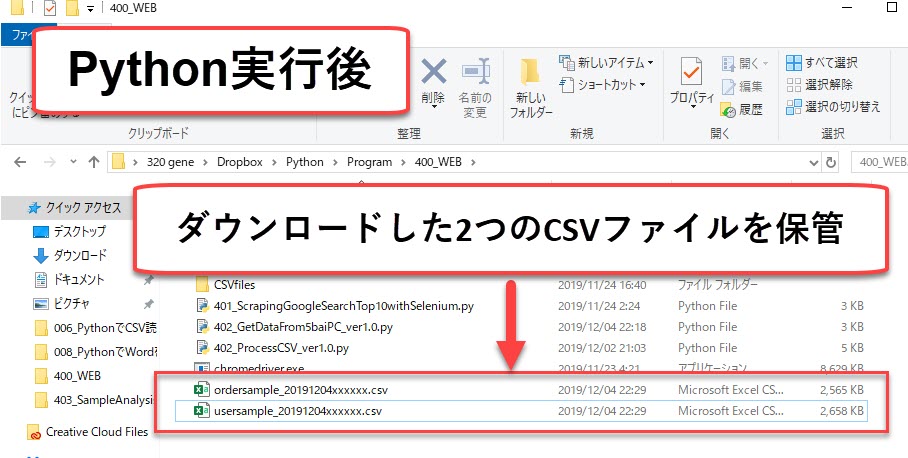
上記のように、私はPythonを使って売上データのCSVファイルをダウンロードさせています。
ちなみに、これらのCSVファイルをダウンロード後に、CSVファイルを解析するプログラムを動かして、その月の売上データをchatツールに出力するようにしています。
この記事では、CSVファイルのダウンロードからchatツールの報告まで、実現方法を紹介していきます。
目次
Pythonで「CSVファイルをダウンロードしchatツールへ出力する」までの全体概要
まず、この記事で紹介する「CSVファイルをダウンロードしchatツールへ出力する」までの全体概要をお伝えします。
ステップ1|自社ウェブサイトからCSVファイルをダウンロードしてフォルダに保管
ステップ2|CSVファイルを解析して1ヶ月分の売上データを解析してChatツールへ出力
ステップ3|ステップ1~ステップ2が月初に起動するように設定
月初にCSVファイルをウェブサイトからダウンロードする
月初になると、タスクスケジューラからPythonプログラムが起動し、以下のとおりチャットに1ヶ月分の売上データが出力されます。
たとえば、月初である2019/12/1になるとCSVファイルをダウンロードするように設定しています。
ステップ2とステップ3は別の記事で紹介します
本記事では、ステップ1とステップ3については解説していません。その2つについては別記事で解説をします。
具体的には以下の表をご覧ください。
| ステップ | 内容 | 実現方法 |
|---|---|---|
| 1 | 自社ウェブサイトからCSVファイルをダウンロードしてフォルダに保管 | 本記事でプログラムを紹介 |
| 2 | CSVファイルを解析して1ヶ月分の売上データを解析してChatツールへ出力 | 別記事でプログラムを紹介 |
| 3 | ステップ1~ステップ3が月初に起動するように設定 | タスクスケジューラ(別記事で紹介) |
ステップ1|自社ウェブサイトからCSVファイルをダウンロードしてフォルダに保管
ログインが必要なウェブサイトからCSVファイルをダウンロードするプログラムは以下です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
# プログラム1|ライブラリの設定 import os from selenium import webdriver import time # プログラム2|mainプログラムのプロシージャ def main(): # プログラム2-1|Inputs(List型)にログイン用パラメータを設定 Inputs = ["あなたのメールアドレス", "パスワード"] # プログラム2-2|必要なファイルパスを入力 path = os.getcwd() Exefile= path + "\\chromedriver.exe" # プログラム2-3|Inputs(List型)にログイン用パラメータを設定 driver = webdriver.Chrome(executable_path=Exefile) # プログラム2-4|Enable_download_in_headless_chromeを呼び出す Enable_download_in_headless_chrome(driver, path) # プログラム2-5|ウェブページにブラウザ操作でログイン driver.get("自社ウェブサイトのURL(ログイン用のテキストボックスがあるURL)") #ログインURL driver.find_element_by_id('UserMail').send_keys(Inputs[0]) driver.find_element_by_id('UserPassword').send_keys(Inputs[1]) driver.find_element_by_class_name('box-login-submit').click() # プログラム2-6|CSVファイルをダウンロードする driver.get("https://xxxxx/download_csv1") #CSVダウンロード用のURLを入れる time.sleep(3) #ダウンロードに要する時間を確保する(ファイルの重さに応じて調整。1GBにつき1秒) driver.get("https://yyyyy/download_csv2") #CSVダウンロード用のURLを入れる time.sleep(3) #ダウンロードに要する時間を確保する(ファイルの重さに応じて調整。1GBにつき1秒) # プログラム2-7|プログラム終了の合図 print("successful") # プログラム3|Enable_download_in_headless_chromeのプロシージャ def Enable_download_in_headless_chrome(driver, path): driver.command_executor._commands["send_command"] = ("POST", '/session/$sessionId/chromium/send_command') params = {'cmd': 'Page.setDownloadBehavior', 'params': {'behavior': 'allow', 'downloadPath': path}} driver.execute("send_command", params) # プログラム4|プログラム開始のおまじない if __name__ == '__main__': main() |
以下で各プログラムについて解説をしていきます。
プログラム1|ライブラリの設定
|
1 2 3 4 |
# プログラム1|ライブラリの設定 import os from selenium import webdriver import time |
この記事で紹介するプログラムでは、上記のライブラリを使用します。以下で各ライブラリについて説明します。
フォルダパスの指定で使用
ウェブブラウザ操作で使用
プログラム停止で使用
上記の内、seleniumはインストールしておく必要があります。
以下の文をコマンドプロンプトで実行することでインストールことができます。
プログラム2|mainプログラムのプロシージャ
|
1 2 |
# プログラム2|mainプログラムのプロシージャ def main(): |
mainという名前のプロシージャの開始点を指す。以下プログラム2は、mainプロシージャの中身を指す。
プログラム2-1|Inputs(List型)にログイン用パラメータを設定
|
1 2 |
# プログラム2-1|Inputs(List型)にログイン用パラメータを設定 Inputs = ["あなたのメールアドレス", "パスワード"] |
「Inputs」というList型の変数に、”あなたのメールアドレス”と”パスワード”をセットする。
この2つは、プログラム2-5でログインするときに使用する。
プログラム2-2|必要なファイルパスを入力
|
1 2 3 |
# プログラム2-2|必要なファイルパスを入力 path = os.getcwd() Exefile= path + "\\chromedriver.exe" |
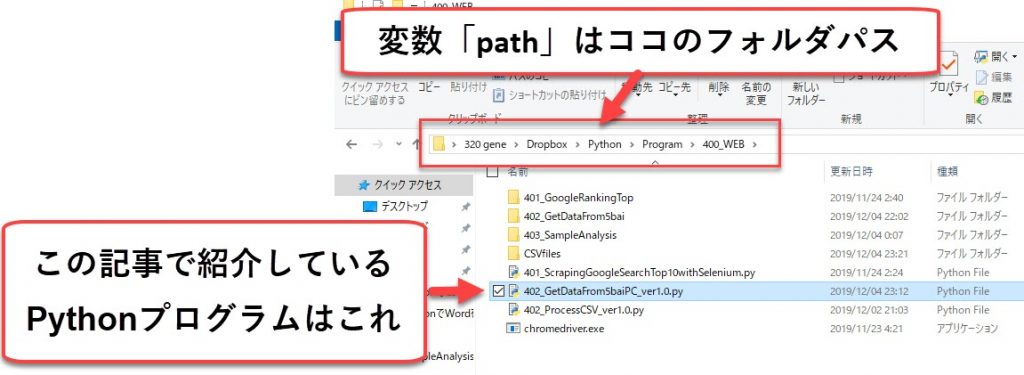
変数「path」を本Pythonプログラムが保管されているフォルダパスにする
ちなみに私のPCの場合、以下のフォルダが「path」が指定するフォルダパスとなる。
変数「Exefile」に「chromedriver.exe」のフォルダパスを指定する

なお、本プログラムでは「chromedriver.exe」をあらかじめダウンロードしておく必要があります。
こちらのURLからChromeDriverをダウンロードします。
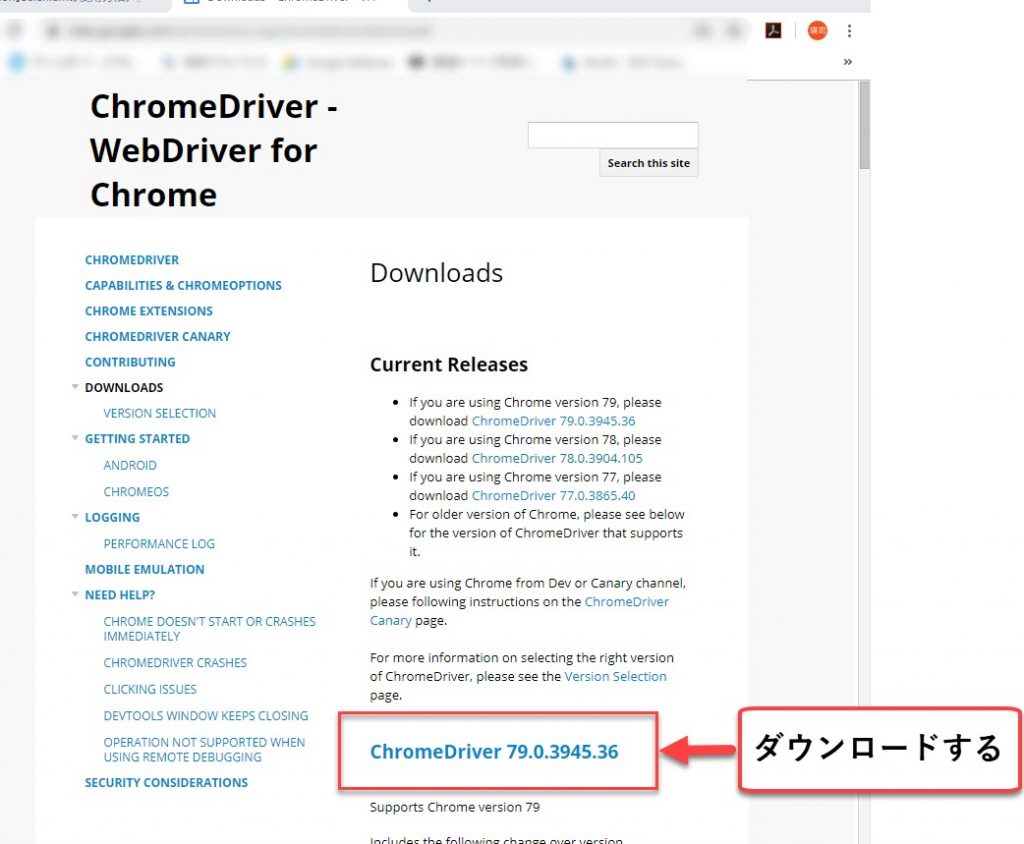
ダウンロードが完了したら、Pythonプログラムと同じフォルダに「chromedriver.exe」を移動しておきます。
プログラム2-3|Chromeを起動する
|
1 2 |
# プログラム2-3|Chromeを起動する driver = webdriver.Chrome(executable_path=Exefile) |
変数「driver」でchromeを起動します。引数である「executable_path」には「chromedriver.exe」のファイルパスをセットします。
ここではプログラム2-2で示した通り、Exefileが「chromedriver.exe」のファイルパスがセットされているので、Exefileを入力しています。
プログラム2-4|関数Enable_download_in_headless_chrome(プログラム3)を呼び出す
|
1 2 |
# プログラム2-4|関数Enable_download_in_headless_chromeを呼び出す Enable_download_in_headless_chrome(driver, path) |
プログラム3を呼び出します。引数として、driverとpathの2つを渡します。
なおプログラム3は、ダウンロードするCSVファイルの保管フォルダ先を取得するためのプログラムです。
プログラム2-5|ウェブページにブラウザ操作でログイン
|
1 2 3 4 5 |
# プログラム2-5|ウェブページにブラウザ操作でログイン driver.get("自社ウェブサイトのURL(ログイン用のテキストボックスがあるURL)") driver.find_element_by_id('UserMail').send_keys(Inputs[0]) driver.find_element_by_id('UserPassword').send_keys(Inputs[1]) driver.find_element_by_class_name('box-login-submit').click() |
ウェブサイトにログインします。ここではログイン用フォームがあるページをURLに指定しています。
以下のようなログイン用フォームがあるURLを()内で指定します。
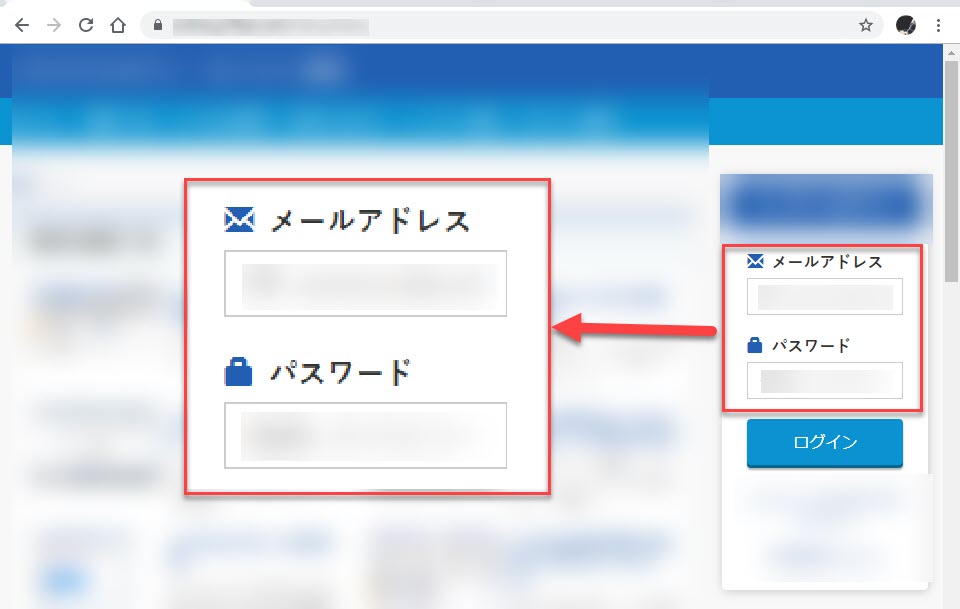
ウェブページで「id=’UserMail’」のHTMLテキストに、プログラム2-1で指定した「Input[0]」を書き込みます。
ちなみにプログラム2-1で、Input[0]にはメールアドレスを格納してあります。
さて、Google chromeではウェブサイトを開いた状態で、「Ctrl + U」のショートカットキーを押すと以下のようにHTMLを確認できます。

このHTMLの中で、ログインに関与している部分を見つけます。
今回、私がターゲットにしたいのは「メールアドレス」、「パスワード」、「ログインボタン」の3つです。
HTMLを確認すると、「メールアドレス」、「パスワード」はid要素で指定されていて、「ログインボタン」はclass要素で指定されていることが分かります。
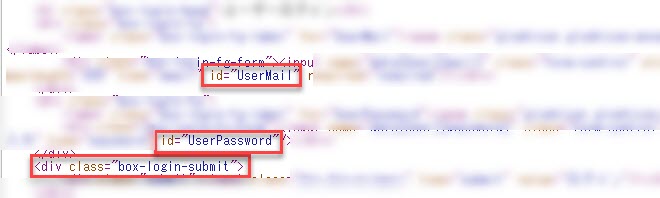
そこで、以下のプログラムを記載します。
“id”が”UserMail”の要素にInputs[0]を入力する
ここでは、「”id”が”UserMail”の要素」はメールアドレスのフォームであり、Inputs[0]はプログラム2-1で示した通り、私のメールアドレスです。
“id”が”UserPassword”の要素にInputs[1]を入力する
ここでは、「”id”が”UserPassword”の要素」はパスワードの入力フォームであり、Inputs[1]はプログラム2-1で示した通り、私のパスワードです。
“class”が”box-login-submit”の要素をclickします。
ここでは、「”class”が”box-login-submit”の要素」はボタンであり、クリックさせることが可能です。
ここまで実行することで、サイトにログインすることが可能です。
プログラム2-6|CSVファイルをダウンロードする
|
1 2 3 4 5 6 7 8 |
# プログラム2-6|CSVファイルをダウンロードする # CSVファイル(1つ目)をダウンロードする driver.get("https://xxxxx/download_csv") time.sleep(3) #ダウンロードに要する時間を確保する(ファイルの重さに応じて調整。1GBにつき1秒) # CSVファイル(2つ目)をダウンロードする driver.get("https://yyyyy/download_csv") time.sleep(3) #ダウンロードに要する時間を確保する(ファイルの重さに応じて調整。1GBにつき1秒) |
()内にCSVをダウンロードするURLを入力します。これで、CSVファイル(1つ目)をダウンロードします。
3秒間、プログラムを停止させます。
目的は、ダウンロードに要する時間を確保するためです。停止時間はファイルの重さに応じて調整。1GBにつき1秒としています。
()内にCSVをダウンロードするURLを入力します。これで、CSVファイル(2つ目)をダウンロードします。
3秒間、プログラムを停止させます。
目的は、ダウンロードに要する時間を確保するためです。停止時間はファイルの重さに応じて調整。1GBにつき1秒としています。
ダウンロードすると、プログラム2-4で指定したフォルダ(path)にダウンロードしたCSVファイルを保存してくれます。
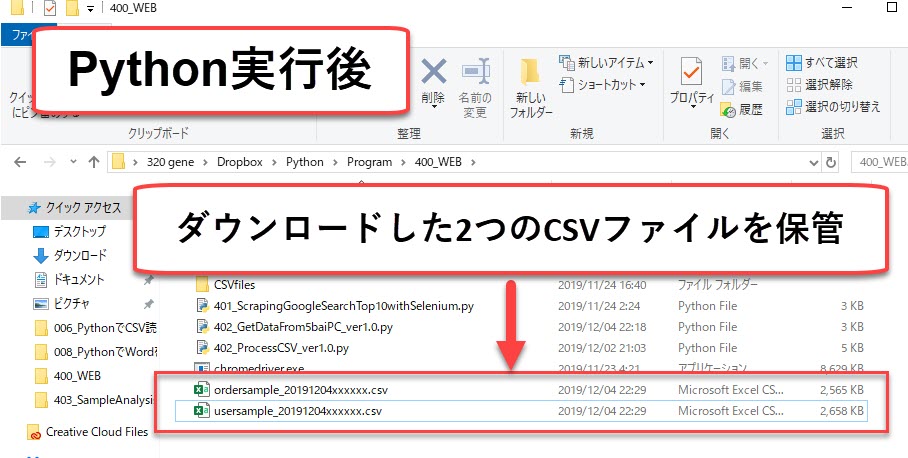
プログラム2-7|プログラム終了の合図
|
1 2 |
# プログラム2-7|プログラム終了の合図 print("successful") |
プログラム終了が分かるように「successful」を出力するように設定
プログラム3|Enable_download_in_headless_chromeのプロシージャ
|
1 2 3 4 5 |
# プログラム3|Enable_download_in_headless_chromeのプロシージャ def Enable_download_in_headless_chrome(driver, path): driver.command_executor._commands["send_command"] = ("POST", '/session/$sessionId/chromium/send_command') params = {'cmd': 'Page.setDownloadBehavior', 'params': {'behavior': 'allow', 'downloadPath': path}} driver.execute("send_command", params) |
本プログラムの目的は、ダウンロードするCSVファイルを保管先となるフォルダパスを指定することにあります。
保管先のフォルダパスは2つの引数であるpathです。
その他のプログラムについては特に解説は入れません。
なおファイルをダウンロードする場合、このプログラム3を入れないと保管先を指定できません。
プログラム4|プログラムを動かすときのおまじない
|
1 2 3 |
#プログラム4|プログラムを動かすときのおまじない if __name__ == "__main__": main() |
このプログラムはおまじないとして、このように書くと覚えてそのまま使うようにしておくと良いです。
詳しい説明は他のサイトに譲ります。
ここで、ステップ1のプログラム解説は終了です。
ステップ2|CSVファイルを解析して1ヶ月分の売上データを解析してChatツールへ出力
ステップ2は以下の記事で詳しく解説をしています。

ステップ2の流れをカンタンに説明しておきます。
1. ステップ1でダウンロードしたCSVファイルの読込
2. Pandasを使ってCSVを処理し、売上データを種類別に算出
3. Chatwork(チャットツール)に出力
上記を実行するプログラムを詳しく解説しています。
ステップ1とステップ2を組み合わせることで毎月の報告をPythonプログラムに実行させることが可能です。
このメリットは、自分が売上データの算出方法を忘れてもプログラムがやってくれることです。
また、誰かに引き継がなくても処理を実行してくれることです。
実際、手順をすぐに忘れてしまう私にとっては、重宝しています。
ステップ3|ステップ1~ステップ2が月初に起動するようにタスクスケジューラを設定
ここで紹介したプログラムは毎月1日起動するように設定しています。
なぜなら一つ前の月の売上データをチャットに通知するからです。たとえば、今日が2019/12/1であれば、「2019/11/1~2019/11/30の売上データを出力する」のです。
ただし、今日が2019/12/1であることの判定はPC側にやってもらう必要があります。
そこで、windowsPCを使っている私はタスクスケジューラに毎月1日に、ステップ1とステップ2のプログラムが起動するように設定しています。
タスクスケジューラにセットして、毎月プログラムを動かす方法は別記事で紹介します。
Python学習に興味がある人へ
ここまでPythonプログラムについて紹介してきました。
Pythonの処理を上手く組み合わせることで、定期的に実行する処理を自動化することができます。
こうすることで月初の作業を忘れずに、かつ正確に実行できます。
ここでは、売上データの定期実行を紹介しましたが、Pythonを使えば他にも様々な作業を効率化できます。
それらについては別の記事で紹介をしているので、興味がある人はそちらをご覧ください。